We want to know the “sensitive of the Cost Function Co to small changes in w . This way, we know how to update the value of w to minimize/modify the value of Co and get close to our target y
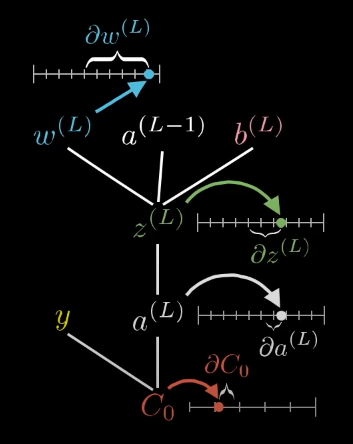

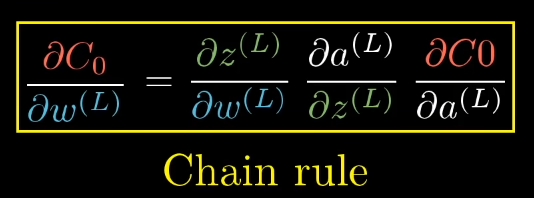

The partial derivatives can be calculated:
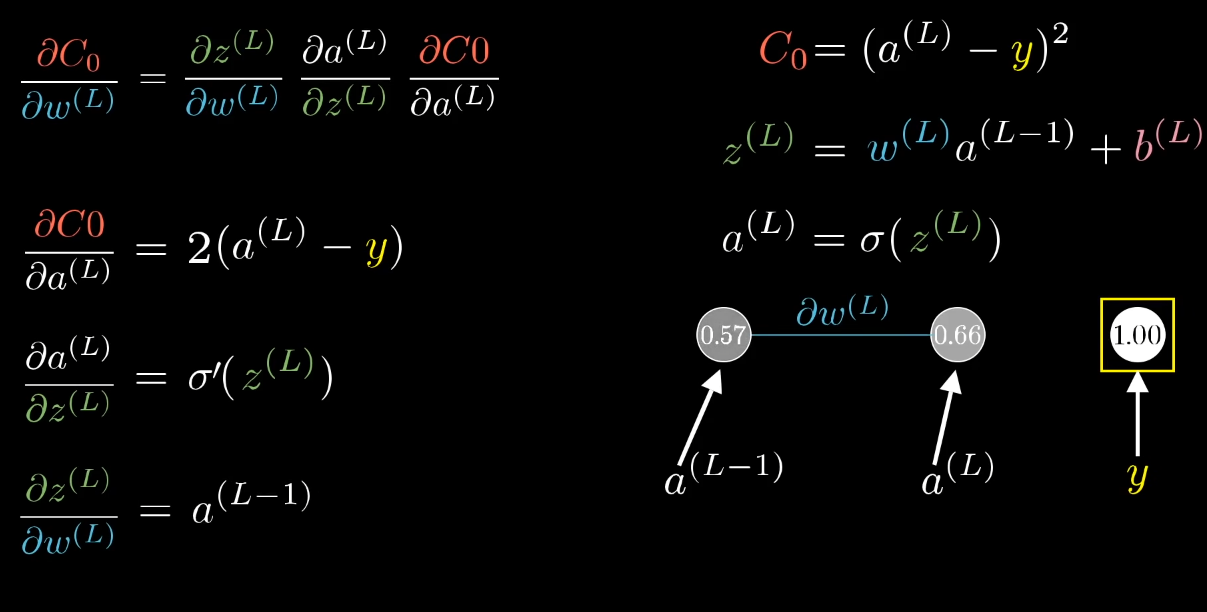
But that’s just half of the way, because we need to actually calculate something called “Gradient Vector”, that contain the partial derivatives of all the weights and bias
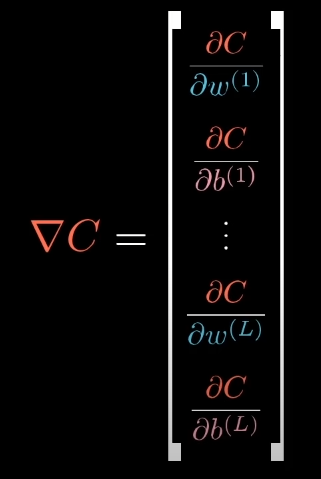
Now, here comes the idea of backpropagation… We can know how sensitive the cost function is to the activation of the previus layers and previus biases (and of course, be able to update them!!!) :
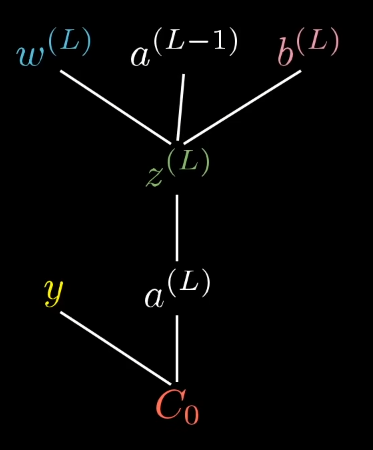
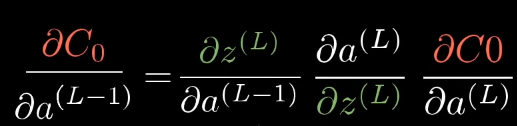
These chain rules expressions give you the derivatives that determine each component in the gradient that helps minimize the cost of the network by repeatedly stepping downhill.
https://www.youtube.com/watch?v=tIeHLnjs5U8