if it’s raining outside, you probably don’t need to know exactly how many droplets of water are falling per second — you just wonder whether it’s raining lightly or heavily. Similarly, neural network predictions often don’t require the precision of floating point calculations with 32-bit or even 16-bit numbers. With some effort, you may be able to use 8-bit integers to calculate a neural network prediction and still maintain the appropriate level of accuracy.
Quantization is an optimization technique that uses an 8-bit integer to approximate an arbitrary value between a preset minimum and a maximum value. For more details, see How to Quantize Neural Networks with TensorFlow.
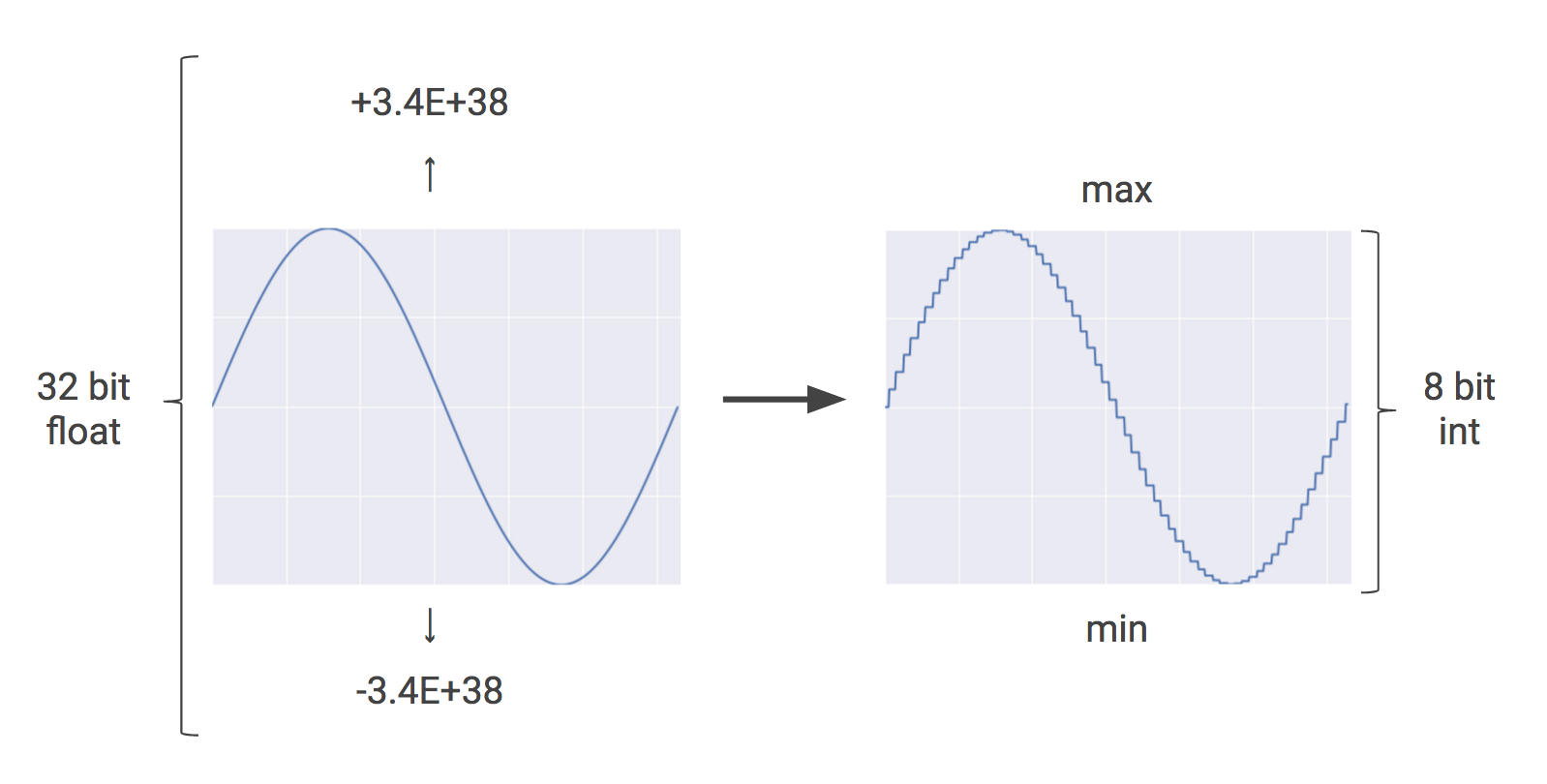
Quantization is a powerful tool for reducing the cost of neural network predictions, and the corresponding reductions in memory usage are important as well, especially for mobile and embedded deployments. For example, when you apply quantization to Inception, the popular image recognition model, it gets compressed from 91MB to 23MB, about one-fourth the original size.