Autoencoders are an unsupervised learning technique in which we leverage neural networks for the task of representation learning (dimensional reduction for example).
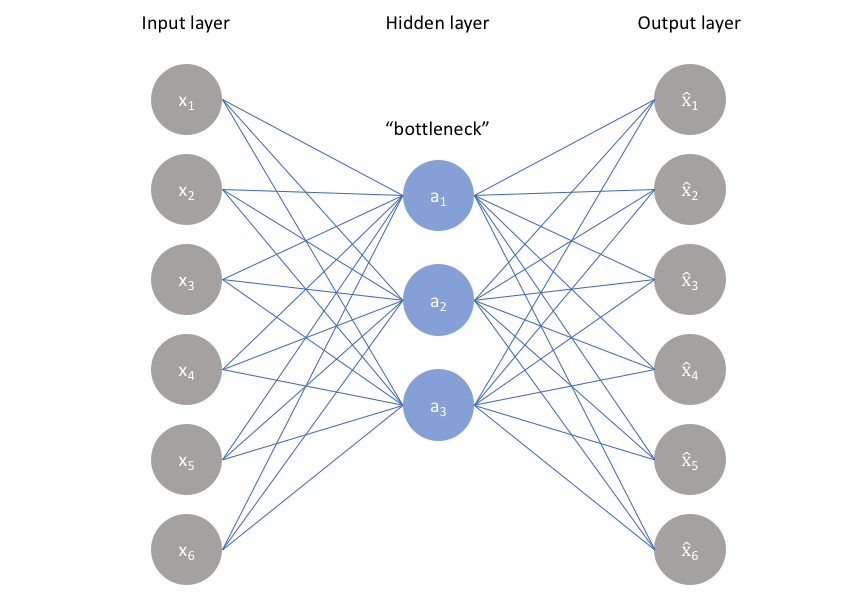
Specifically, we’ll design a neural network architecture such that we impose a bottleneck in the network which forces a compressed knowledge representation of the original input.
If the input features were each independent of one another, this compression and subsequent reconstruction would be a very difficult task. However, if some sort of structure exists in the data (ie. correlations between input features), this structure can be learned and consequently leveraged when forcing the input through the network’s bottleneck.
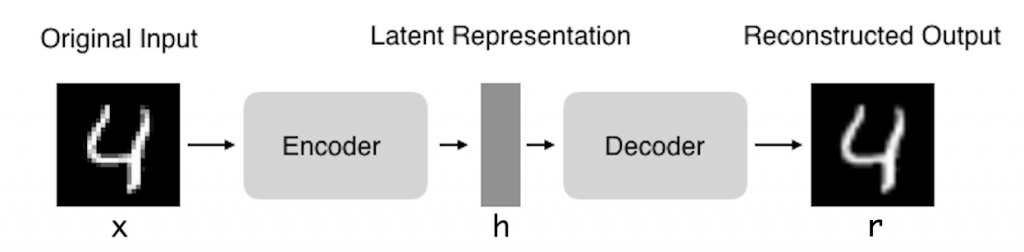
In fact, we hope that by training the Autoencoder to copy the input to the output, the latent representation h will have useful properties.
This can be achieved by creating restrictions on the copy. One way to get useful Autoencoder features is to constrain h to have dimensions smaller than x, in this case, the Autoencoder is called incomplete. By training an incomplete representation, we force the Autoencoder to learn the most important features of the training data.
This behavior makes the autoencoder a good choice for tasks of data denoising or data dimension reduction (such as PCA).
As visualized above, we can take an unlabeled dataset and frame it as a supervised learning problem tasked with outputting x^, a **reconstruction of the original input **x. This network can be trained by minimizing the reconstruction error:
which measures the differences between our original input and the consequent reconstruction.
Note: In fact, if we were to construct a linear network we would observe a similar dimensionality reduction as observed in PCA.
The ideal autoencoder model balances the following:
- Sensitive to the inputs enough to accurately build a reconstruction.
- Insensitive enough to the inputs that the model doesn’t simply memorize or overfit the training data.
This trade-off forces the model to maintain only the variations in the data required to reconstruct the input without holding on to redundancies within the input. For most cases, this involves constructing a loss function where one term encourages our model to be sensitive to the inputs and a second term discourages memorization/overfitting:
We’ll typically add a scaling parameter in front of the regularization term so that we can adjust the trade-off between the two objectives.
PCA VS AUTOENCODERS
Because neural networks are capable of learning nonlinear relationships, this can be thought of as a more powerful (nonlinear) generalization of PCA. Whereas PCA attempts to discover a lower dimensional hyperplane which describes the original data, autoencoders are capable of learning nonlinear manifolds (a manifold is defined in *simple *terms as a continuous, nointersecting surface). The difference between these two approaches is visualized below.
https://www.jeremyjordan.me/autoencoders/
DENOISING
Recall that I mentioned we’d like our autoencoder to be sensitive enough to recreate the original observation but insensitive enough to the training data such that the model learns a generalizable encoding and decoding.
Another approach towards developing a generalizable model is to slightly corrupt the input data but still maintain the uncorrupted data as our target output.
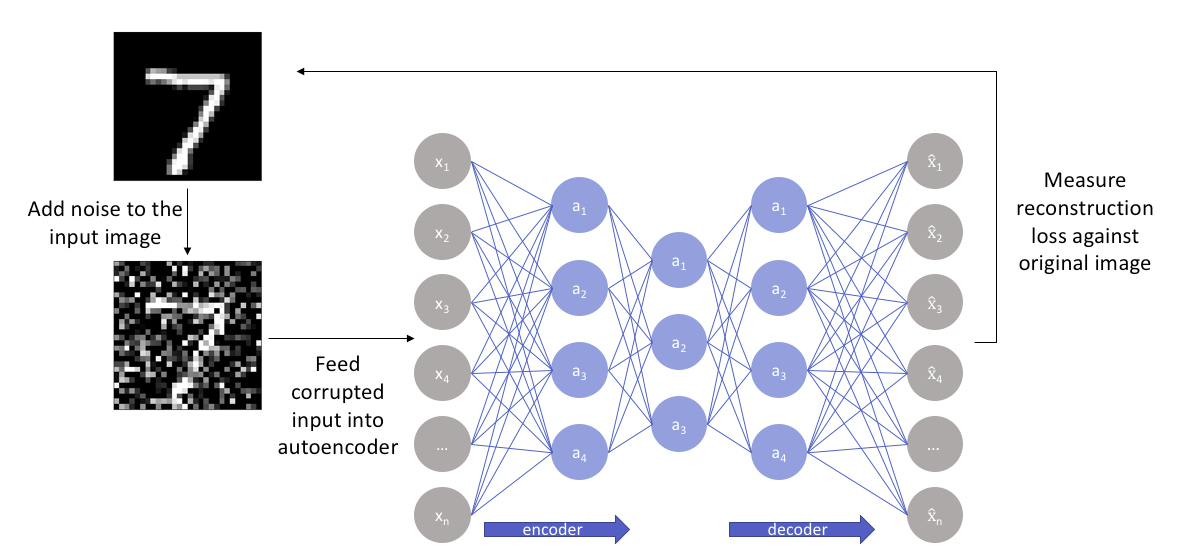
With this approach, the** model isn’t able to simply develop a mapping which memorizes the training data because our input and target output are no longer the same**.