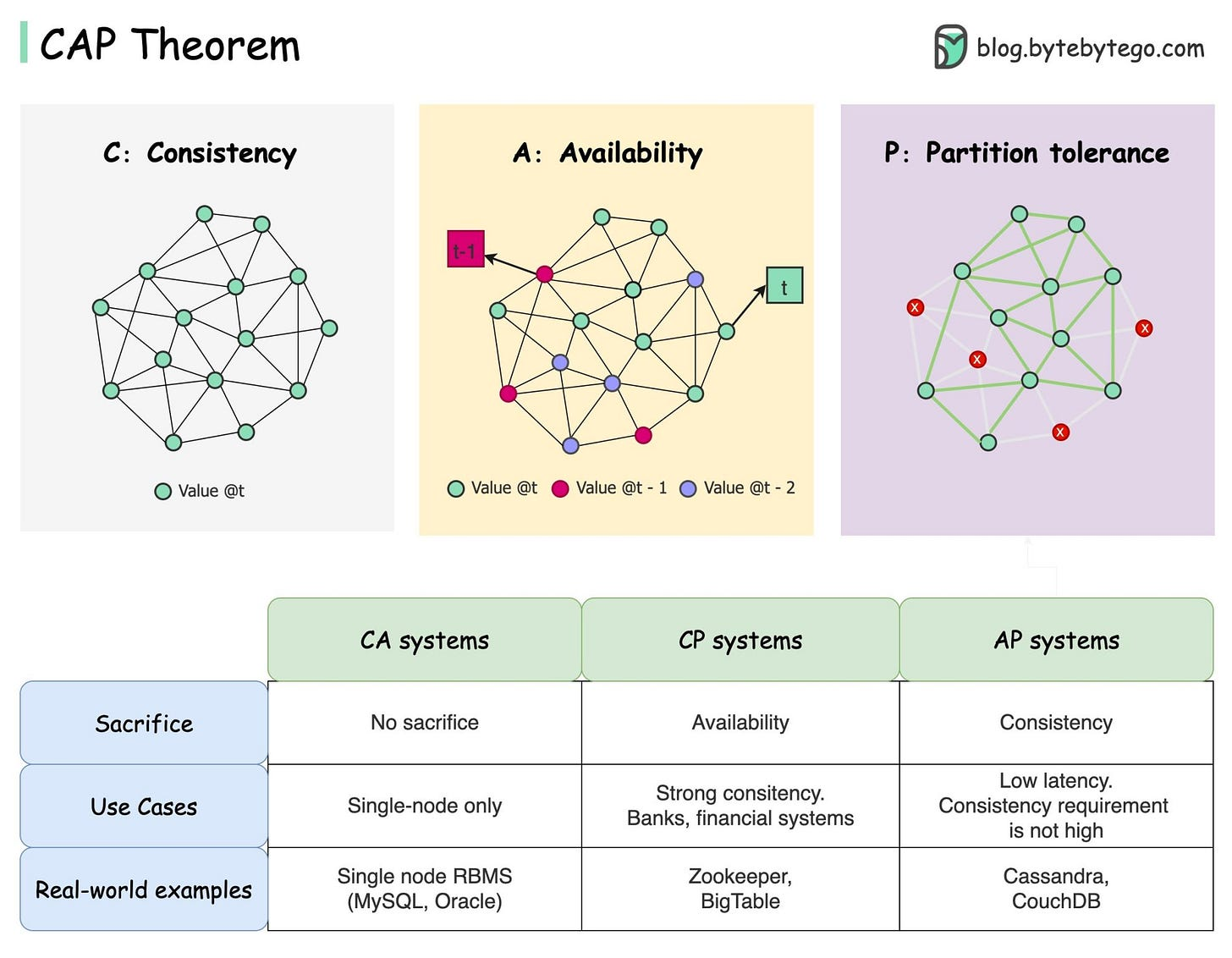
CAP Theorem: a shared-data system can have at most two of the three following properties: Consistency, Availability, and tolerance to network
CRITICS
The CAP theorem isn’t something you can build a system out of. It’s not a theorem you can take as a first principle and derive a working system from. It’s much too general in its purview, and the space of possible solutions too broad.
However, it is well-suited for critiquing a distributed system design, and understanding what trade-offs need to be made. Taking a system design and iterating through the constraints CAP puts on its subsystems will leave you with a better design at the end. For homework, apply the CAP theorem’s constraints to a real world implementation of Russian-doll caching.
TL;DR
Of the CAP theorem’s Consistency, Availability, and Partition Tolerance, Partition Tolerance is mandatory in distributed systems. You cannot **not **choose it. Instead of CAP, you should think about your availability in terms of *yield *(percent of requests answered successfully) and *harvest *(percent of required data actually included in the responses) and which of these two your system will sacrifice when failures happen.
A Readjustment In Focus
I think part of the problem with practical interpretations of the CAP theorem, especially with Gilbert and Lynch’s formulation, is the fact that most real distributed systems do not require atomic consistency or perfect availability and will never be called upon to perform on a network suffering from arbitrary message loss.
https://codahale.com/you-cant-sacrifice-partition-tolerance/
Consistency, Availability, and Partition Tolerance are the Platonic ideals of a distributed system–we can partake of them enough to meet business requirements, but the nature of reality is such that there will always be compromises.
When it comes to designing or evaluating distributed systems, then, I think we should focus less on which two of the three Virtues we like most and more on what compromises a system makes as things go bad.
I think there are four conclusions that should be drawn from the CAP theorem:
-
Many system designs used in early distributed relational database systems did not take into account partition tolerance* *(e.g. they were CA designs).
- Partition tolerance is an important property for modern systems, since network partitions become much more likely if the system is geographically distributed
-
There is a tension between strong consistency and high availability during network partitions. 2. The CAP theorem is an illustration of the tradeoffs that occur between strong guarantees and distributed computation. 3. In some sense, it is quite crazy to promise that a distributed system consisting of independent nodes connected by an unpredictable network “behaves in a way that is indistinguishable from a non-distributed system”.
-
There is a tension between strong consistency and performance in normal operation**.** 4. Strong consistency / single-copy consistency requires that nodes communicate and agree on every operation. This results in high latency during normal operation. 5. If you can live with a consistency model other than the classic one, a consistency model that allows replicas to lag or to diverge, then you can reduce latency during normal operation and maintain availability in the presence of partitions. 6. When fewer messages and fewer nodes are involved, an operation can complete faster. But the only way to accomplish that is to relax the guarantees: let some of the nodes be contacted less frequently, which means that nodes can contain old data. 7. This also makes it possible for anomalies to occur. You are no longer guaranteed to get the most recent value. Depending on what kinds of guarantees are made, you might read a value that is older than expected, or even lose some updates.
-
If we do not want to give up availability during a network partition, then we need to explore whether consistency models other than strong consistency are workable for our purposes**.** 8. Consistency and availability are not really binary choices, unless you limit yourself to strong consistency. But strong consistency is just one consistency model: the one where you, by necessity, need to give up availability in order to prevent more than a single copy of the data from being active. As Brewer himself points out, the “2 out of 3” interpretation is misleading.
http://book.mixu.net/distsys/abstractions.html
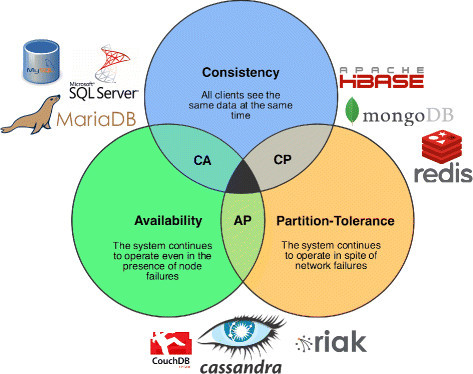
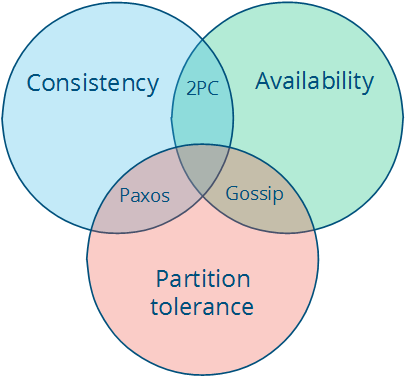
The CA and CP system designs both offer the same consistency model: strong consistency. The only difference is that a CA system cannot tolerate any node failures; a CP system can tolerate up to f faults given 2f+1 nodes in a non-Byzantine failure model (in other words, it can tolerate the failure of a minority f of the nodes as long as majority f+1 stays up). The reason is simple:
-
A CA system does not distinguish between node failures and network failures, and hence must stop accepting writes everywhere to avoid introducing divergence (multiple copies). It cannot tell whether a remote node is down, or whether just the network connection is down: so the only safe thing is to stop accepting writes.
-
A CP system prevents divergence (e.g. maintains single-copy consistency) by forcing asymmetric behavior on the two sides of the partition. It only keeps the majority partition around, and requires the minority partition to become unavailable (e.g. stop accepting writes), which retains a degree of availability (the majority partition) and still ensures single-copy consistency.

https://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed/
https://apple.github.io/foundationdb/cap-theorem.html