ACID consistency != CAP consistency != Oatmeal consistency
(The “C” in CAP is “strong consistency”, but “consistency” is not a synonym for “strong consistency”)
Algorithms
- Paxos – Variants :- multi-paxos, cheap paxos, fast paxos, generalised paxos
- Raft
- Practical Byzantine Fault Tolerance algorithm (PBFT)
- Proof of Work (PoW)
- Proof-of-Stake algorithm (PoS)
- Proof of Burn (PoB)
- Delegated Proof-of-Stake algorithm (DPoS)
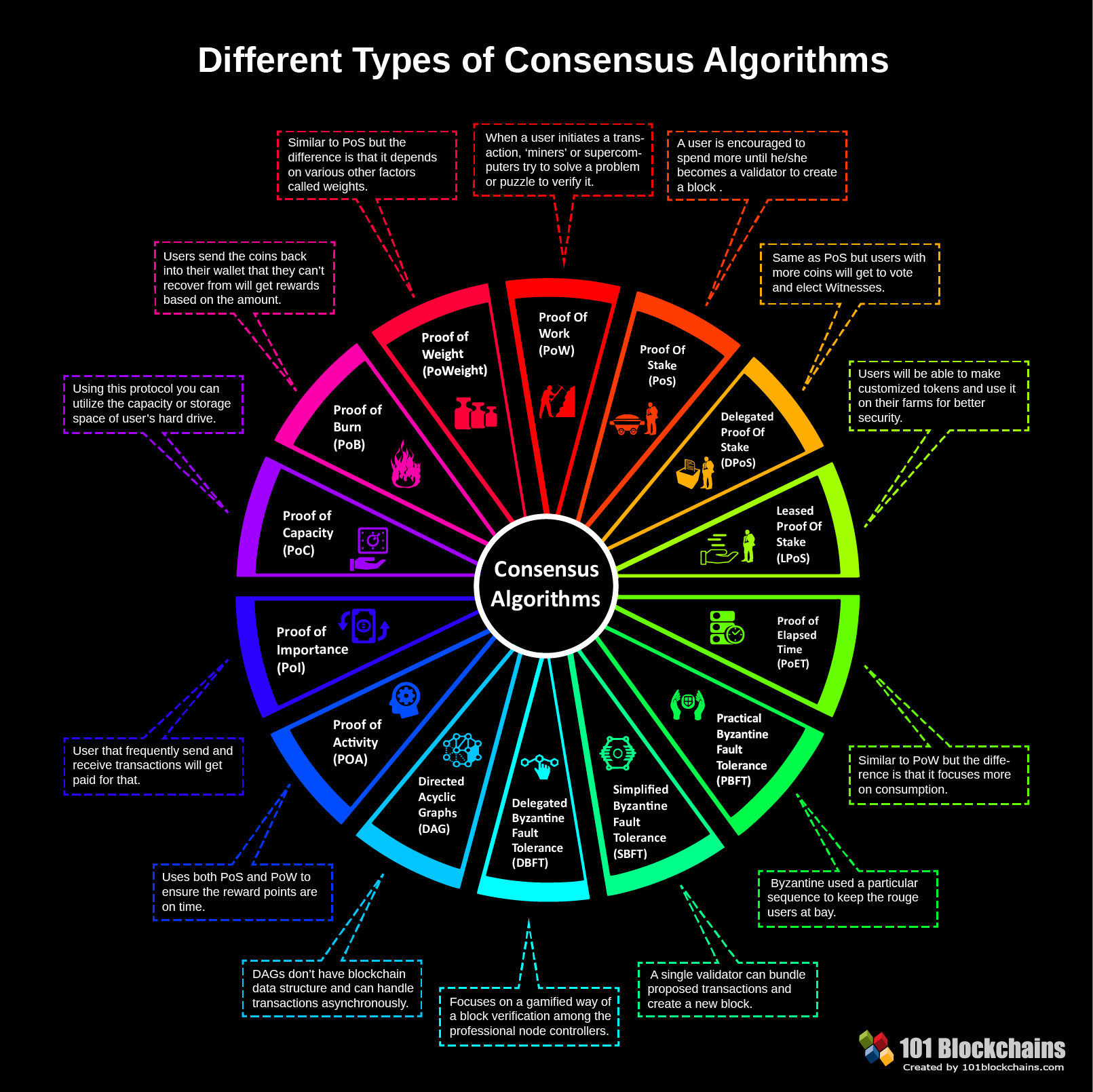
Consensus
A consensus algorithm is an algorithm that allows multiple participating nodes to agree on a common truth. Usually, this is done using sequence of messages submitted by external clients.
One example of a system for Distributed Consensus at the core of many Distributed Systems (for example etcd, (the Databases backing Kubernetes) and many Hashicorp tools it the Raft Protocol.
It is for example used by Canonical’s dqlite replicated database (distributed SQLite).
Consistency Models
Consistency models can be categorized into two types: strong and weak consistency models
http://book.mixu.net/distsys/abstractions.html
Consistency models are just arbitrary contracts between the programmer and system, so they can be almost anything.
STRONG
- Strong consistency models (capable of maintaining a single copy):
- Linearizable consistency
- Sequential consistency
From the perspective of a client interacting with a node, the two “strong consistency models” are equivalent.
Strong consistency models guarantee that the apparent order and visibility of updates is equivalent to a non-replicated system.
To have strong consistency, developers must compromise on the scalability and performance of their application. Simply put, data has to be locked during the period of update or replication process to ensure that no other processes are updating the same data. https://medium.com/system-design-blog/eventual-consistency-vs-strong-consistency-b4de1f92534d
Second, that there is a tension between strong consistency and high availability during network partitions. The CAP theorem is an illustration of the tradeoffs that occur between strong guarantees and distributed computation.
Strong consistency guarantees require us to give up availability during a partition. This is because one cannot prevent divergence between two replicas that cannot communicate with each other while continuing to accept writes on both sides of the partition.
Strong consistency models allow you as a programmer to replace a single server with a cluster of distributed nodes and not run into any problems.
Strong consistency / single-copy consistency requires that nodes communicate and agree on every operation. This results in high latency during normal operation.
A conceptual view of the deployment topology and replication process with strong consistency is shown in below figure. In this diagram, you can see how replicas always have values consistent with the originating node, but are not accessible until the update finishes.
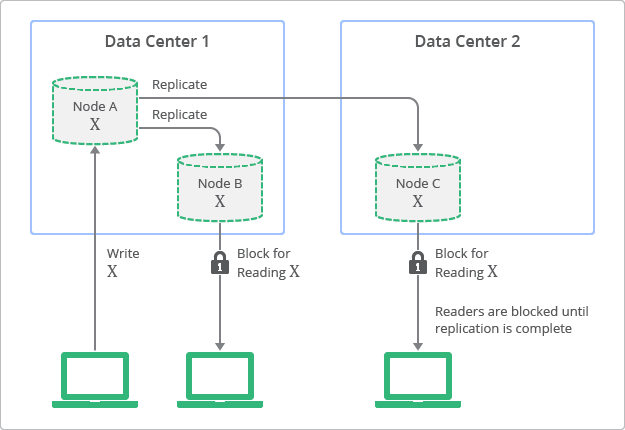
Computation on a single node is easy, because everything happens in a predictable global total order. Computation on a distributed system is difficult, because there is no global total order.
For the longest while (e.g. decades of research), we've solved this problem by introducing a global total order. I’ve discussed the many methods for achieving strong consistency by creating order (in a fault-tolerant manner) where there is no naturally occurring total order. Of course, the problem is that enforcing order is expensive.
- A system enforcing strong consistency doesn’t behave like a distributed system: it behaves like a single system, which is bad for availability during a partition.
So behaving like a single system by default is perhaps not desirable.
WEAK
Perhaps what we want is a system where we can write code that doesn’t use expensive coordination, and yet returns a “usable” value. Instead of having a single truth, we will allow different replicas to diverge from each other - both to keep things efficient but also to tolerate partitions - and then try to find a way to deal with the divergence in some manner.
Weaker consistency means higher availability, performance and throughput although more anomalous data.
- Weak consistency models (not strong)
- Client-centric consistency models
- Causal consistency: strongest model available
- Eventual consistency models
If “consistency” is defined as something less than “all nodes see the same data at the same time” then we can have both availability and some (weaker) consistency guarantee. Eventual consistency expresses this idea: that nodes can for some time diverge from each other, but that eventually they will agree on the value.
Within the set of systems providing eventual consistency, there are two types of system designs:
- Eventual consistency with probabilistic guarantees
- This type of system can detect conflicting writes at some later point, but does not guarantee that the results are equivalent to some correct sequential execution.
- In other words, conflicting updates will sometimes result in overwriting a newer value with an older one and some anomalies can be expected to occur during normal operation (or during partitions).
- Eventual consistency with strong guarantees
- This type of system guarantees that the results converge to a common value equivalent to some correct sequential execution.
- In other words, such systems do not produce any anomalous results; without any coordination you can build replicas of the same service, and those replicas can communicate in any pattern and receive the updates in any order, and they will eventually agree on the end result as long as they all see the same information.
There is a fundamental tradeoff between **latency **and consistency.

https://www.alexdebrie.com/posts/database-consistency/