TL;DR
https://github.com/lizrice/ebpf-beginners
The TL;DR version is that this technology enables sandboxed user applications to run in the Linux kernel itself. In a way it makes the kernel *programmable *which unlocks tremendous possibilities.
- eBPF code is run in a safe virtual machine inside the kernel
You can pick **any function **from the kernel and execute the program every time that function runs. Running a program that “attaches” to network sockets, tracepoints and perf events can be extremely useful. Developers can debug the kernel without having to re-compile it. There are plenty of use cases such as:
eBPF programs are event-driven and are run when the kernel or an application passes a certain hook point. Pre-defined hooks include system calls, function entry/exit, kernel tracepoints, network events, and several others.
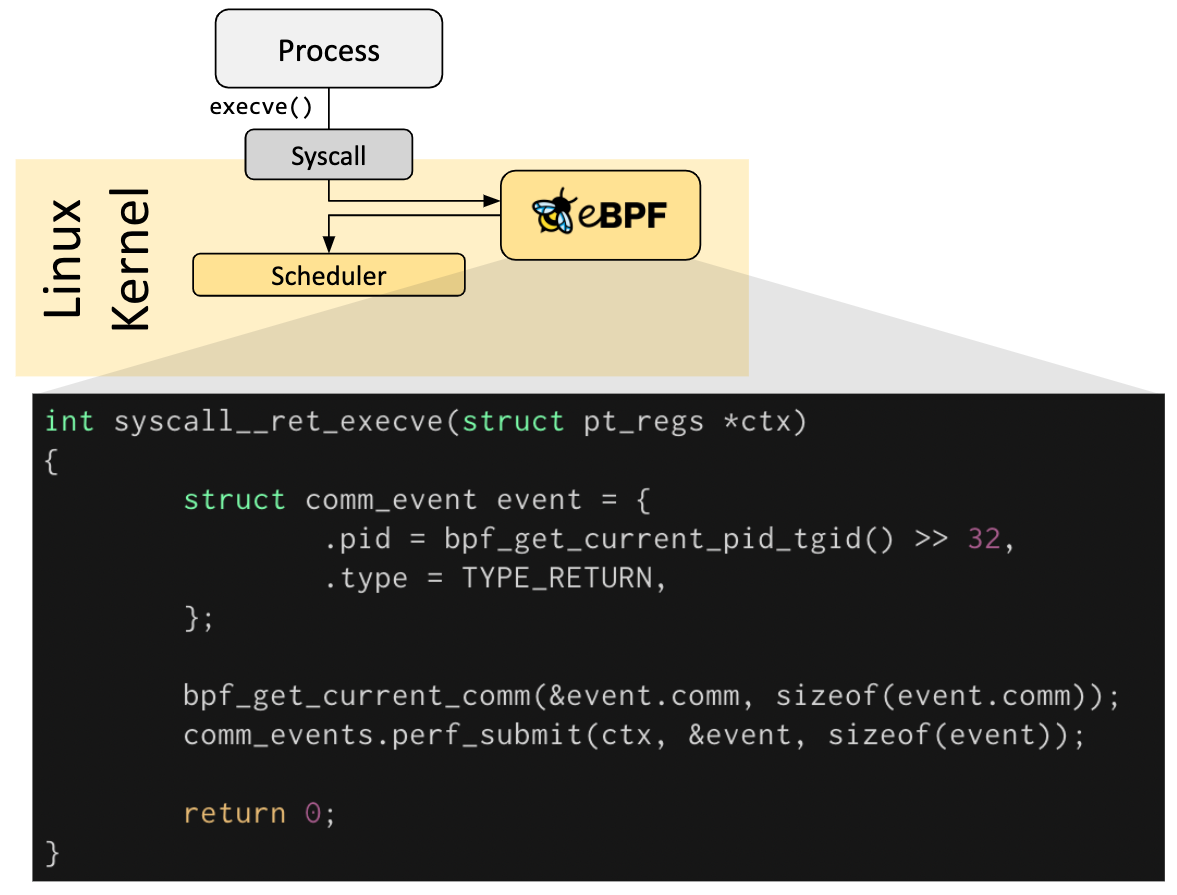
If a predefined hook does not exist for a particular need, it is possible to create a kernel probe (kprobe) or user probe (uprobe) to attach eBPF programs almost anywhere in kernel or user applications.
https://filipnikolovski.com/posts/ebpf/
An eBPF program is just a sequence of 64-bit instructions. The virtual machine’s instruction set is fairly limited and it has two goals in mind:
- The code needs to be executed as fast as possible.
- All BPF instructions must be verifiable at load time to ensure the safety of the kernel.
- eBPF code is run in a safe virtual machine inside the kernel
Writing these programs is done with the help of some frameworks (like bcc
and bpftrace) and the program bytecode is then loaded via the bpf system call.
https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/
https://blogs.oracle.com/linux/post/bpf-a-tour-of-program-types
https://blog.aquasec.com/libbpf-ebpf-programs
https://blog.yadutaf.fr/2016/03/30/turn-any-syscall-into-event-introducing-ebpf-kernel-probes/
https://blog.yadutaf.fr/2014/05/29/introduction-to-seccomp-bpf-linux-syscall-filter/