SINGLE-CORE INITIALIZATION:
- Check if VMX operation is supported by the processor.
- Allocate system and processor specific structures.
- Adjust
CR4andCR0to supported values. - Enable VMX operation on each processor.
- Set feature control bits to allows use of
vmxon. - Execute
vmxon, and enter VMX operation.
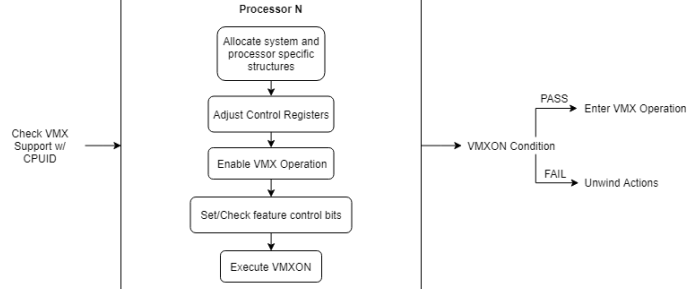
The N in label identifies the processor number that these operations occur. Since these operations are per processor (the IA32_FEATURE_CONTROL MSR has unique scope) they must occur for each virtual processor allocated for the VM.
ALLOCATING SYSTEM AND PROCESSOR CONTEXTS:
The first thing we want to do is refer back to our VMM context structure. This is the structure that maintains a table of all virtual processor contexts in the VM, has our hypervisor stack, and our virtual processor count. We’ll need to allocate our VMM context in the non-paged pool, as well as our vCPU table and stack. We’re also going to initialize our processor_count member to the current active processor count using KeQueryActiveProcessorCountEx.
struct __vmm_context_t *allocate_vmm_context( void )
{
struct __vmm_context_t *vmm_context = NULL;
vmm_context = ( struct __vmm_context_t * )ExAllocatePoolWithTag( NonPagedPool, sizeof( struct __vmm_context_t ), VMM_TAG );
if( vmm_context == NULL ) {
log_error( "Oops! vmm_context could not be allocated.\n" );
return NULL;
}
vmm_context->processor_count = KeQueryActiveProcessorCountEx( ALL_PROCESSOR_GROUPS );
vmm_context->vcpu_table = ExAllocatePoolWithTag( NonPagedPool, sizeof( struct __vcpu_t * ) * vmm_context->processor_count, VMM_TAG );
//
// Allocate stack for vm-exit handlers and fill it with garbage
// data.
//
vmm_context->stack = ExAllocatePoolWithTag( NonPagedPool, VMM_STACK_SIZE, VMM_TAG );
memset( vmm_context->stack, 0xCC, VMM_STACK_SIZE );
log_success( "vmm_context allocated at %llX\n", vmm_context );
log_success( "vcpu_table allocated at %llX\n", vmm_context->vcpu_table );
log_debug( "vmm stack allocated at %llX\n", vmm_context->stack );
return vmm_context;
}The next thing we want to do is create a VMM initialization routine, a function that kicks off the start of virtualization. All it needs to do is call allocate_vmm_context, and then initialize each virtual process context in the table. However, to accomplish this we need to allocate a vCPU table entry on the non-paged pool prior to modifying any data otherwise we’ll be accessing garbage data. Below is the implementation of our vCPU table entry initialization function.
struct __vcpu_t *init_vcpu( void )
{
struct __vcpu_t *vcpu = NULL;
vcpu = ExAllocatePoolWithTag( NonPagedPool, sizeof( struct __vcpu_t ), VMM_TAG );
if( !vcpu ) {
log_error( "Oops! vcpu could not be allocated.\n" );
return NULL;
}
RtlSecureZeroMemory( vcpu, sizeof( struct __vcpu_t ) );
return vcpu;
}VMM initialization routine:
int vmm_init( void )
{
struct __vmm_context_t *vmm_context;
vmm_context = allocate_vmm_context( );
for ( unsigned iter = 0; iter < vmm_context->processor_count; iter++ ) {
vmm_context->vcpu_table[ iter ] = init_vcpu( );
vmm_context->vcpu_table[ iter ]->vmm_context = vmm_context;
}
init_logical_processor( vmm_context, 0 );
return TRUE;
}Part of the __vcpu_t structure is a back link to the VMM context that way I can obtain peripheral virtual processor information in any functions that I may need to. The init_logical_processor function isn’t defined yet, however, we’re going to define it below as that is where we’ll initialize the VMXON and VMCS regions and execute vmxon:
(Check the page links for this regions initialization routines)
Function Prototype:
void init_logical_processor( struct __vmm_context_t *context, void *guest_rsp )
Inside of this function we’ll need to be able to access information in the VMM context, use the vCPU table to get the current virtual processor table entry, and query the current processor number so that we can index into the vCPU table to get the proper entry.
void init_logical_processor( struct __vmm_context_t *context, void *guest_rsp )
{
struct __vmm_context_t *vmm_context;
struct __vcpu_t *vcpu;
union __vmx_misc_msr_t vmx_misc;
unsigned long processor_number;
processor_number = KeGetCurrentProcessorNumber( );
vmm_context = ( struct __vmm_context_t * )context;
vcpu = vmm_context->vcpu_table[ processor_number ];
log_debug( "vcpu %d guest_rsp = %llX\n", processor_number, guest_rsp );
adjust_control_registers( );
if( !is_vmx_supported( ) ) {
log_error( "VMX operation is not supported on this processor.\n" );
free_vmm_context( vmm_context );
return;
}
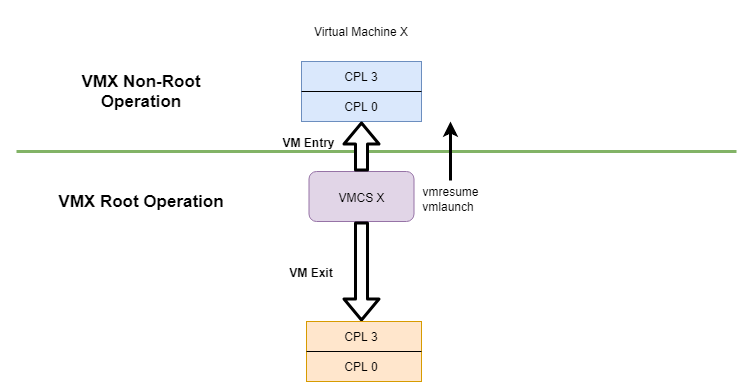
if( !init_vmxon( vcpu ) ) {
log_error( "VMXON failed to initialize for vcpu %d.\n", processor_number );
free_vcpu( vcpu );
disable_vmx( );
return;
}
if( __vmx_on( &vcpu->vmxon_physical ) != 0 ) {
log_error( "Failed to put vcpu %d into VMX operation.\n", KeGetCurrentProcessorNumber( ) );
free_vcpu( vcpu );
disable_vmx( );
free_vmm_context( vmm_context );
return
}
log_success( "vcpu %d is now in VMX operation.\n", KeGetCurrentProcessorNumber( ) );
}MULTIPLE-CORE INITIALIZATION
There are methods for multi core initilization: “Inter-processor Interrupts”, “Affinity Masks” and “Deferred Procedure Calls” (Windows DPC).
Affinity Masks** (easy)**
- An affinity mask is a bit mask that determines what processor a thread should be run on. Processor affinity refers to the binding of a thread to a specific processing unit so that the thread will run on the designated processor. To initialize the VMM on each virtual processor we can modify the processor affinity of the thread executing initialization code to a specific processor. One simple and effective and widely used way is through the use of
**KeSetSystemAffinityThreadEx**. This function does exactly what we described above, sets the processor affinity of the current thread. To restore the original affinity of the thread we call**KeRevertToUserAffinityThreadEx**. - So how can we initialize the VMM on each virtual processor using these operating system routines? Use a for-loop from 0 to the number of processors, set the thread processor affinity to schedule a thread to run on the target processor, execute the initialization code, and revert the threads affinity. This method requires that the IRQL during execution of initialization code be
**DISPATCH_LEVEL**or lower, and to ensure that**NonPagedPool**allocations are all that can be used we’re going to force the IRQL to**DISPATCH_LEVEL**.
{kind=link}
VMM initialization is performed with the assumption that it is operating on a symmetric system. This means that the processors on a system share the memory, I/O bus, and the operating system.
There are considerations to be made when initializing a VMM on a multiprocessor system. The first of which is to ensure that the required features are supported.
Do the following per processor (as per the specification as well):
- Use
cpuidon each virtual processor to determine if VMX is supported. - Check
VMCSandVMXONrevision identifiers for each virtual processor. - Check the VMX capability MSR’s of each virtual processor for value restrictions (allowed 0, or 1 bits).
- Allocate and initialize
VMXONandVMCSregions on each virtual processor. - Adjust
CR0andCR4to support all fixed bits reported in the fixed MSR’s. - Enable
VMX operationon each virtual processor. - Validate that the
**IA32_FEATURE_CONTROL**MSR has been properly programmed and the lock bit set. - Execute
VMXONfor each virtual processor. - Error handling.
We need to implement our MP virtualization protocol in vmm_init first. Since we’re going to be modifying the processor affinity and assigning which group of processors we’re going to initialize on we’ll need to declare a few variables with type GROUP_AFFINITY, and PROCESSOR_NUMBER. We’re also going to use KeGetProcessorNumberFromIndex to acquire a system-wide processor index from a group number and group-relative processor number. Since this system routine takes a processor index that identifies a processor on the entire multiprocessor system we’re going to pass in our iteration number. This works because a MP system can have groups (as an example a system with four groups, each group having 64 processors, has group ranges from 0 to 64 processors, and system-wide indexes from 0-255).
int vmm_init( void )
{
struct __vmm_context_t *vmm_context;
PROCESSOR_NUMBER processor_number;
GROUP_AFFINITY affinity, old_affinity;
KIRQL old_irql;
vmm_context = allocate_vmm_context( );
for ( unsigned iter = 0; iter < vmm_context->processor_count; iter++ ) {
vmm_context->vcpu_table[ iter ] = init_vcpu( );
vmm_context->vcpu_table[ iter ]->vmm_context = vmm_context;
}
for( unsigned iter = 0; iter < vmm_context->processor_count; iter++ ) {
//
// Convert from an index to a processor number.
//
KeGetProcessorNumberFromIndex( iter, &processor_number );
RtlSecureZeroMemory( &affinity, sizeof( GROUP_AFFINITY ) );
affinity.Group = processor_number.Group;
affinity.Mask = ( KAFFINITY )1 << processor_number.Number;
KeSetSystemGroupAffinityThread( &affinity, &old_affinity );
init_logical_processor( vmm_context, 0 );
KeRevertToUserGroupAffinityThread( &old_affinity );
}
return TRUE;
}If you recall from the VM-Execution Control Fields section we briefly talked about MSR bitmap, this bitmap is used to control which MSR’s cause a VM exit when rdmsr or wrmsr is used on them. We don’t want to exit on any MSR accesses for this project, so we need to allocate an MSR bitmap (recall it is 4-KByte in size) and zero it out so that all bits in the bitmap are 0.
First we need to add two members to our __vcpu_t structure. It should now look like this:
struct __vcpu_t
{
struct __vmcs_t *vmcs;
unsigned __int64 vmcs_physical;
struct __vmcs_t *vmxon;
unsigned __int64 vmxon_physical;
void *msr_bitmap;
unsigned __int64 msr_bitmap_physical;
};Remember that we provided the MSR bitmaps physical address to the VMCS component when initializing the VMCS and having both the VA and PA is important for tracking and memory management purposes.
In our init_vcpu routine we’re going to allocate the MSR bitmap, zero it, and store the corresponding information in the new __vcpu_t members. The init_vcpu function should now resemble this:
struct __vcpu_t *init_vcpu( void )
{
struct __vcpu_t *vcpu = NULL;
vcpu = ExAllocatePoolWithTag( NonPagedPool, sizeof( struct __vcpu_t ), VMM_TAG );
if( !vcpu ) {
log_error( "Oops! vcpu could not be allocated.\n" );
return NULL;
}
RtlSecureZeroMemory( vcpu, sizeof( struct __vcpu_t ) );
//
// Zero out msr bitmap so that no traps occur on MSR accesses
// when in guest operation.
//
vcpu->msr_bitmap = ExAllocatePoolWithTag( NonPagedPool, PAGE_SIZE, VMM_TAG );
RtlSecureZeroMemory( vcpu->msr_bitmap, PAGE_SIZE );
vcpu->msr_bitmap_physical = MmGetPhysicalAddress( vcpu->msr_bitmap ).QuadPart;
log_debug( "vcpu entry allocated successfully at %llX\n", vcpu );
return vcpu;
}