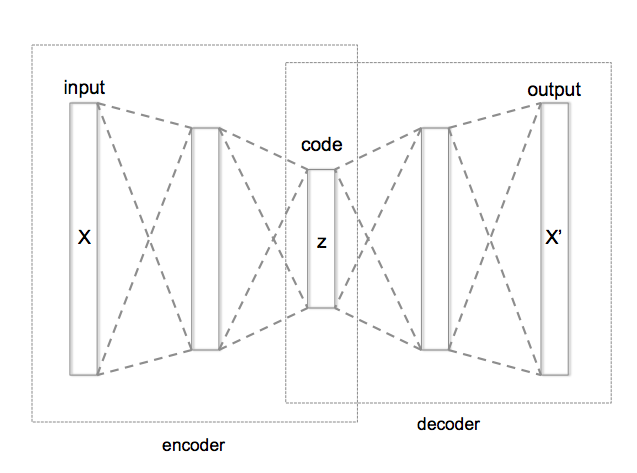
Autoencoder architecture
Let’s design autoencoder as two sequential keras models: the encoder and decoder respectively.
We will then use symbolic API to apply and train these models.

def build_pca_autoencoder(img_shape, code_size):
"""
Here we define a simple linear autoencoder as described above.
We also flatten and un-flatten data to be compatible with image shapes
"""
encoder = keras.models.Sequential()
encoder.add(L.InputLayer(img_shape))
encoder.add(L.Flatten()) # flatten image to vector
encoder.add(L.Dense(code_size)) # actual encoder
decoder = keras.models.Sequential()
decoder.add(L.InputLayer((code_size,)))
decoder.add(L.Dense(np.prod(img_shape))) # actual decoder, height*width*3 units
decoder.add(L.Reshape(img_shape)) # un-flatten
return encoder,decoders = tf.compat.v1.Session()
encoder, decoder = build_pca_autoencoder(IMG_SHAPE, code_size=32)
inp = L.Input(IMG_SHAPE)
code = encoder(inp)
reconstruction = decoder(code)
autoencoder = keras.models.Model(inputs=inp, outputs=reconstruction)
autoencoder.compile(optimizer='adamax', loss='mse')
autoencoder.fit(x=X_train, y=X_train, epochs=15,
validation_data=[X_test, X_test],
verbose=0)def visualize(img,encoder,decoder):
"""Draws original, encoded and decoded images"""
code = encoder.predict(img[None])[0] # img[None] is the same as img[np.newaxis, :]
reco = decoder.predict(code[None])[0]
plt.subplot(1,3,1)
plt.title("Original")
show_image(img)
plt.subplot(1,3,2)
plt.title("Code")
plt.imshow(code.reshape([code.shape[-1]//2,-1]))
plt.subplot(1,3,3)
plt.title("Reconstructed")
show_image(reco)
plt.show()
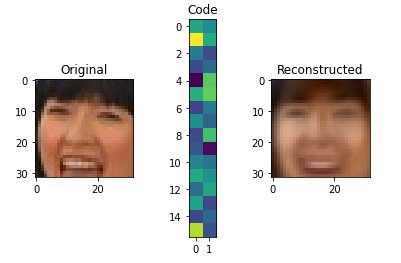
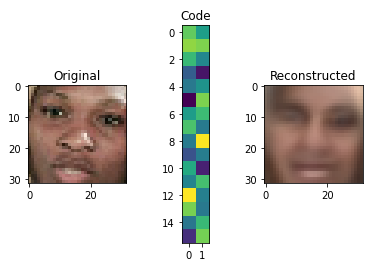
score = autoencoder.evaluate(X_test,X_test,verbose=0)
print("PCA MSE:", score)
for i in range(5):
img = X_test[i]
visualize(img,encoder,decoder)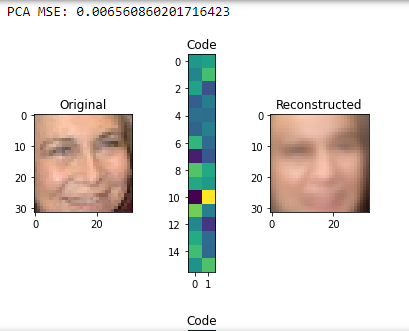
Going deeper: convolutional autoencoder
PCA is neat but surely we can do better. This time we want to build a deep convolutional autoencoder by… stacking more layers.
Encoder
The encoder part is pretty standard, we stack convolutional and pooling layers and finish with a dense layer to get the representation of desirable size (code_size).
It’s recommend to use activation='elu' for all convolutional and dense layers.
It’s recommended to repeat (conv, pool) 4 times with kernel size (3, 3), padding='same' and the following numbers of output channels: 32, 64, 128, 256.
Remember to flatten (L.Flatten()) output before adding the last dense layer!
Decoder
For decoder we will use so-called “transpose convolution”.
Traditional convolutional layer takes a patch of an image and produces a number (patch → number). In “transpose convolution” we want to take a number and produce a patch of an image (number → patch). We need this layer to “undo” convolutions in encoder.
Here’s how “transpose convolution” works:
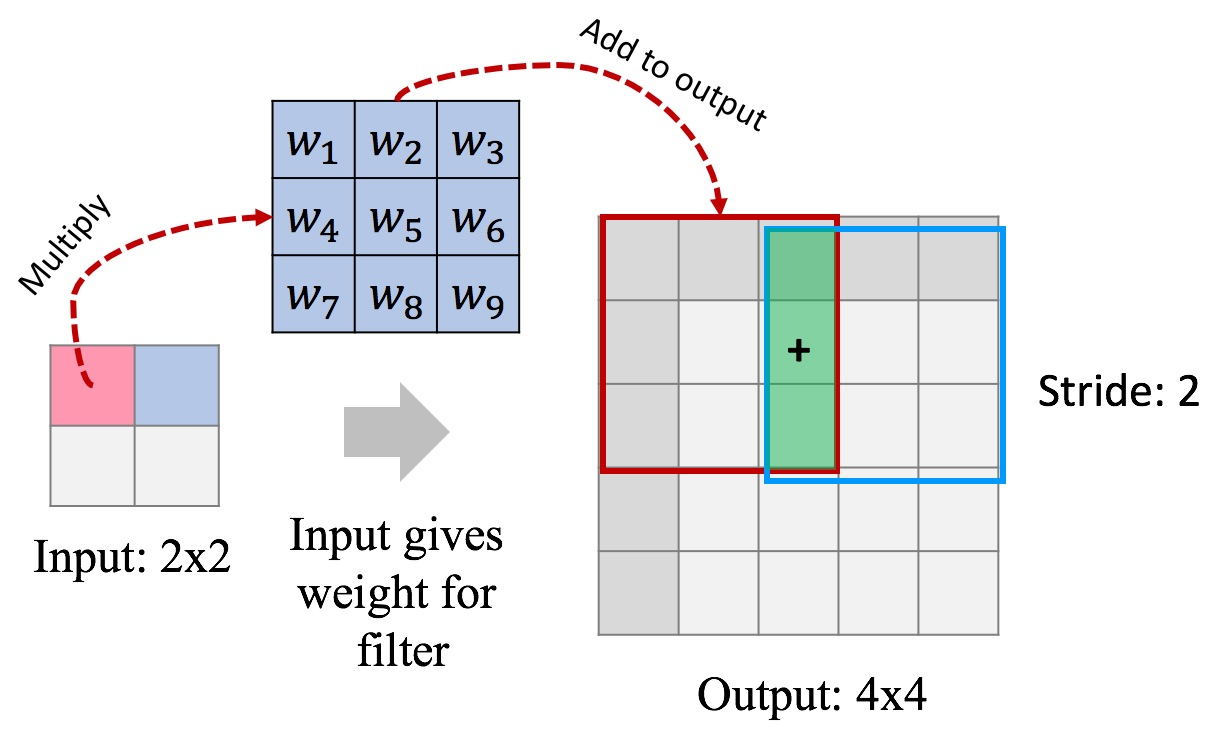
In this example we use a stride of 2 to produce 4x4 output, this way we “undo” pooling as well. Another way to think about it: we “undo” convolution with stride 2 (which is similar to conv + pool).
You can add “transpose convolution” layer in Keras like this:
L.Conv2DTranspose(filters=?, kernel_size=(3, 3), strides=2, activation='elu', padding='same')Our decoder starts with a dense layer to “undo” the last layer of encoder. Remember to reshape its output to “undo” L.Flatten() in encoder.
Now we’re ready to undo (conv, pool) pairs. For this we need to stack 4 L.Conv2DTranspose layers with the following numbers of output channels: 128, 64, 32, 3. Each of these layers will learn to “undo” (conv, pool) pair in encoder. For the last L.Conv2DTranspose layer use activation=None because that is our final image.
# Let's play around with transpose convolution on examples first
def test_conv2d_transpose(img_size, filter_size):
print("Transpose convolution test for img_size={}, filter_size={}:".format(img_size, filter_size))
x = (np.arange(img_size ** 2, dtype=np.float32) + 1).reshape((1, img_size, img_size, 1))
f = (np.ones(filter_size ** 2, dtype=np.float32)).reshape((filter_size, filter_size, 1, 1))
# s = tf.compat.v1.Session()
conv = tf.nn.conv2d_transpose(x, f,
output_shape=(1, img_size * 2, img_size * 2, 1),
strides=[1, 2, 2, 1],
padding='SAME')
result = conv
#result = s.run(conv)
print("input:")
print(x[0, :, :, 0])
print("filter:")
print(f[:, :, 0, 0])
print("output:")
print(result[0, :, :, 0])
#s.close()
test_conv2d_transpose(img_size=2, filter_size=2)
test_conv2d_transpose(img_size=2, filter_size=3)
test_conv2d_transpose(img_size=4, filter_size=2)
test_conv2d_transpose(img_size=4, filter_size=3)def build_deep_autoencoder(img_shape, code_size):
"""PCA's deeper brother. See instructions above. Use `code_size` in layer definitions."""
H,W,C = img_shape
# encoder
encoder = keras.models.Sequential()
encoder.add(L.InputLayer(img_shape))
### YOUR CODE HERE: define encoder as per instructions above ###
encoder.add(L.Conv2D(32, (3, 3), strides = (1, 1), padding="same", activation='elu'))
encoder.add(L.MaxPooling2D((2, 2)))
encoder.add(L.Conv2D(64, (3, 3), strides = (1, 1), padding="same", activation='elu'))
encoder.add(L.MaxPooling2D((2, 2)))
encoder.add(L.Conv2D(128, (3, 3), strides = (1, 1), padding="same", activation='elu'))
encoder.add(L.MaxPooling2D((2, 2)))
encoder.add(L.Conv2D(256, (3, 3), strides = (1, 1), padding="same", activation='elu'))
encoder.add(L.MaxPooling2D((2, 2)))
encoder.add(L.Flatten()) #flatten image to vector
encoder.add(L.Dense(code_size)) #actual encoder
# decoder
decoder = keras.models.Sequential()
decoder.add(L.InputLayer((code_size,)))
### YOUR CODE HERE: define decoder as per instructions above ###
decoder.add(L.Dense(2*2*256)) #actual encoder
decoder.add(L.Reshape((2,2,256))) #un-flatten
decoder.add(L.Conv2DTranspose(filters=128, kernel_size=(3, 3), strides=2, activation='elu', padding='same'))
decoder.add(L.Conv2DTranspose(filters=64, kernel_size=(3, 3), strides=2, activation='elu', padding='same'))
decoder.add(L.Conv2DTranspose(filters=32, kernel_size=(3, 3), strides=2, activation='elu', padding='same'))
decoder.add(L.Conv2DTranspose(filters=3, kernel_size=(3, 3), strides=2, activation=None, padding='same'))
return encoder, decoder# Check autoencoder shapes along different code_sizes
get_dim = lambda layer: np.prod(layer.output_shape[1:])
for code_size in [1,8,32,128,512]:
# s = reset_tf_session()
encoder, decoder = build_deep_autoencoder(IMG_SHAPE, code_size=code_size)
print("Testing code size %i" % code_size)
assert encoder.output_shape[1:]==(code_size,),"encoder must output a code of required size"
assert decoder.output_shape[1:]==IMG_SHAPE, "decoder must output an image of valid shape"
assert len(encoder.trainable_weights)>=6, "encoder must contain at least 3 layers"
assert len(decoder.trainable_weights)>=6, "decoder must contain at least 3 layers"
for layer in encoder.layers + decoder.layers:
assert get_dim(layer) >= code_size, "Encoder layer %s is smaller than bottleneck (%i units)"%(layer.name,get_dim(layer))
print("All tests passed!")
# s = reset_tf_session()# Look at encoder and decoder shapes.
# Total number of trainable parameters of encoder and decoder should be close.
# s = reset_tf_session()
encoder, decoder = build_deep_autoencoder(IMG_SHAPE, code_size=32)
encoder.summary()
decoder.summary()# s = reset_tf_session()
encoder, decoder = build_deep_autoencoder(IMG_SHAPE, code_size=32)
inp = L.Input(IMG_SHAPE)
code = encoder(inp)
reconstruction = decoder(code)
autoencoder = keras.models.Model(inputs=inp, outputs=reconstruction)
autoencoder.compile(optimizer="adamax", loss='mse')
autoencoder.fit(x=X_train, y=X_train, epochs=25,
validation_data=[X_test, X_test],
callbacks=[keras_utils.ModelSaveCallback(model_filename)],
verbose=0,
initial_epoch=last_finished_epoch or 0)
reconstruction_mse = autoencoder.evaluate(X_test, X_test, verbose=0)
print("Convolutional autoencoder MSE:", reconstruction_mse)
for i in range(5):
img = X_test[i]
visualize(img,encoder,decoder)
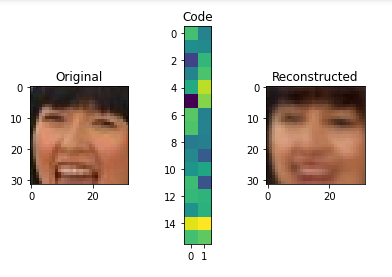
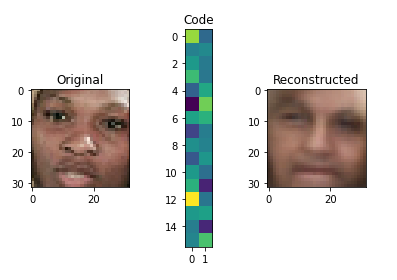
Denoising Autoencoder
Let’s now turn our model into a denoising autoencoder:
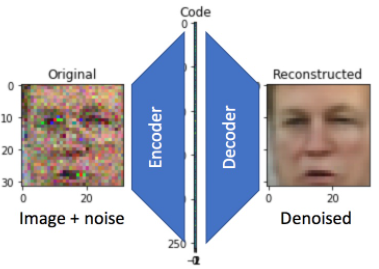
We’ll keep the model architecture, but change the way it is trained. In particular, we’ll corrupt its input data randomly with noise before each epoch.
There are many strategies to introduce noise: adding gaussian white noise, occluding with random black rectangles, etc. We will add gaussian white noise.
def apply_gaussian_noise(X, sigma=0.1):
"""
adds noise from standard normal distribution with standard deviation sigma
:param X: image tensor of shape [batch,height,width,3]
Returns X + noise.
"""
noise = np.random.normal(0, sigma, X.shape)
return X + noise# test different noise scales
plt.subplot(1,4,1)
show_image(X_train[0])
plt.subplot(1,4,2)
show_image(apply_gaussian_noise(X_train[:1],sigma=0.01)[0])
plt.subplot(1,4,3)
show_image(apply_gaussian_noise(X_train[:1],sigma=0.1)[0])
plt.subplot(1,4,4)
show_image(apply_gaussian_noise(X_train[:1],sigma=0.5)[0])
# s = reset_tf_session()
# we use bigger code size here for better quality
encoder, decoder = build_deep_autoencoder(IMG_SHAPE, code_size=512)
assert encoder.output_shape[1:]==(512,), "encoder must output a code of required size"
inp = L.Input(IMG_SHAPE)
code = encoder(inp)
reconstruction = decoder(code)
autoencoder = keras.models.Model(inp, reconstruction)
autoencoder.compile('adamax', 'mse')
for i in range(25):
print("Epoch %i/25, Generating corrupted samples..."%(i+1))
X_train_noise = apply_gaussian_noise(X_train)
X_test_noise = apply_gaussian_noise(X_test)
# we continue to train our model with new noise-augmented data
autoencoder.fit(x=X_train_noise, y=X_train, epochs=1,
validation_data=[X_test_noise, X_test],
verbose=0)X_test_noise = apply_gaussian_noise(X_test)
denoising_mse = autoencoder.evaluate(X_test_noise, X_test, verbose=0)
print("Denoising MSE:", denoising_mse)
for i in range(5):
img = X_test_noise[i]
visualize(img,encoder,decoder)