import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
plt.rcParams.update({'axes.titlesize': 'small'})
from sklearn.datasets import load_digits
#The following line fetches you two datasets: images, usable for autoencoder training and attributes.
#Those attributes will be required for the final part of the assignment (applying smiles), so please keep them in mind
from lfw_dataset import load_lfw_dataset
data,attrs = load_lfw_dataset(dimx=36,dimy=36)
#preprocess faces
data = np.float32(data)/255.
IMG_SHAPE = data.shape[1:]#print random image
plt.imshow(data[np.random.randint(data.shape[0])], cmap="gray", interpolation="none")
Deep learning is simple, isn’t it?
- build some network that generates the face (small image)
- make up a measure of how good that face is
- optimize with gradient descent :)
The only problem is: how can we engineers tell well-generated faces from bad? And i bet you we won’t ask a designer for help.
If we can’t tell good faces from bad, we delegate it to yet another neural network!
That makes the two of them:
-
Generator - takes random noize for inspiration and tries to generate a face sample.
- Let’s call him G(z), where z is a gaussian noize.
-
Discriminator - takes a face sample and tries to tell if it’s great or fake.
- Predicts the probability of input image being a real face
- Let’s call him D(x), x being an image.
- D(x) is a predition for real image and D(G(z)) is prediction for the face made by generator.
Before we dive into training them, let’s construct the two networks.
#import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
from keras_utils import reset_tf_session
# s = reset_tf_session()
import keras
from keras.models import Sequential
from keras import layers as LCODE_SIZE = 256
generator = Sequential()
generator.add(L.InputLayer([CODE_SIZE],name='noise'))
generator.add(L.Dense(10*8*8, activation='elu'))
generator.add(L.Reshape((8,8,10)))
generator.add(L.Conv2DTranspose(64,kernel_size=(5,5),activation='elu'))
generator.add(L.Conv2DTranspose(64,kernel_size=(5,5),activation='elu'))
generator.add(L.UpSampling2D(size=(2,2)))
generator.add(L.Conv2DTranspose(32,kernel_size=3,activation='elu'))
generator.add(L.Conv2DTranspose(32,kernel_size=3,activation='elu'))
generator.add(L.Conv2DTranspose(32,kernel_size=3,activation='elu'))
generator.add(L.Conv2D(3,kernel_size=3,activation=None))Discriminator
- Discriminator is your usual convolutional network with interlooping convolution and pooling layers
- The network does not include dropout/batchnorm to avoid learning complications.
- We also regularize the pre-output layer to prevent discriminator from being too certain.
discriminator = Sequential()
discriminator.add(L.InputLayer(IMG_SHAPE))
discriminator.add(L.Conv2D(8, (3, 3)))
discriminator.add(L.LeakyReLU(0.1))
discriminator.add(L.Conv2D(16, (3, 3)))
discriminator.add(L.LeakyReLU(0.1))
discriminator.add(L.MaxPool2D())
discriminator.add(L.Conv2D(32, (3, 3)))
discriminator.add(L.LeakyReLU(0.1))
discriminator.add(L.Conv2D(64, (3, 3)))
discriminator.add(L.LeakyReLU(0.1))
discriminator.add(L.MaxPool2D())
discriminator.add(L.Flatten())
discriminator.add(L.Dense(256,activation='tanh'))
discriminator.add(L.Dense(2,activation=tf.nn.log_softmax))Training
We train the two networks concurrently:
- Train discriminator to better distinguish real data from current generator
- Train generator to make discriminator think generator is real
- Since discriminator is a differentiable neural network, we train both with gradient descent.
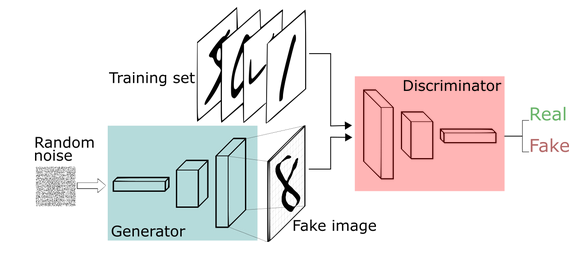
Training is done iteratively until discriminator is no longer able to find the difference (or until you run out of patience).
Tricks:
- Regularize discriminator output weights to prevent explosion
- Train generator with adam to speed up training. Discriminator trains with SGD to avoid problems with momentum.
- More: https://github.com/soumith/ganhacks
noise = tf.placeholder(np.float32,[None,CODE_SIZE])
real_data = tf.placeholder(np.float32,[None,]+list(IMG_SHAPE))
logp_real = discriminator(real_data)
generated_data = generator(noise)
logp_gen = discriminator(generated_data)########################
#discriminator training#
########################
d_loss = -tf.reduce_mean(logp_real[:,1] + logp_gen[:,0])
#regularize
d_loss += tf.reduce_mean(discriminator.layers[-1].kernel**2)
#optimize
disc_optimizer = tf.train.GradientDescentOptimizer(1e-3).minimize(d_loss,var_list=discriminator.trainable_weights)########################
###generator training###
########################
g_loss = -tf.reduce_mean(logp_gen[:,1])
gen_optimizer = tf.train.AdamOptimizer(1e-4).minimize(g_loss,var_list=generator.trainable_weights)Auxiliary functions
Here we define a few helper functions that draw current data distributions and sample training batches.
def sample_noise_batch(bsize):
return np.random.normal(size=(bsize, CODE_SIZE)).astype('float32')
def sample_data_batch(bsize):
idxs = np.random.choice(np.arange(data.shape[0]), size=bsize)
return data[idxs]
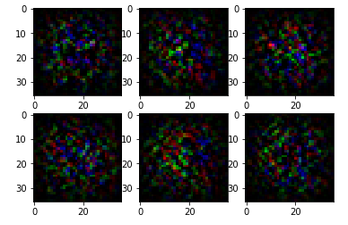
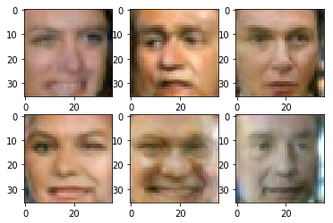
def sample_images(nrow,ncol, sharp=False):
images = generator.predict(sample_noise_batch(bsize=nrow*ncol))
if np.var(images)!=0:
images = images.clip(np.min(data),np.max(data))
for i in range(nrow*ncol):
plt.subplot(nrow,ncol,i+1)
if sharp:
plt.imshow(images[i].reshape(IMG_SHAPE),cmap="gray", interpolation="none")
else:
plt.imshow(images[i].reshape(IMG_SHAPE),cmap="gray")
plt.show()
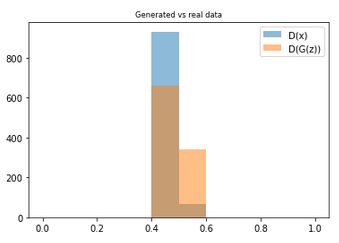
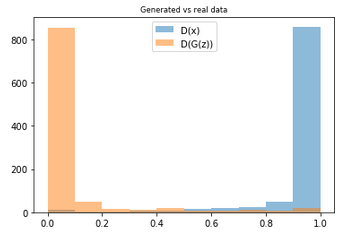
def sample_probas(bsize):
plt.title('Generated vs real data')
plt.hist(np.exp(discriminator.predict(sample_data_batch(bsize)))[:,1],
label='D(x)', alpha=0.5,range=[0,1])
plt.hist(np.exp(discriminator.predict(generator.predict(sample_noise_batch(bsize))))[:,1],
label='D(G(z))',alpha=0.5,range=[0,1])
plt.legend(loc='best')
plt.show()Main loop. We just train generator and discriminator in a loop and plot results once every N iterations.
from IPython import display
for epoch in tqdm_utils.tqdm_notebook_failsafe(range(50000)):
feed_dict = {
real_data:sample_data_batch(100),
noise:sample_noise_batch(100)
}
for i in range(5):
s.run(disc_optimizer,feed_dict)
s.run(gen_optimizer,feed_dict)
if epoch %100==0:
display.clear_output(wait=True)
sample_images(2,3,True)
sample_probas(1000)