WHEN NOT USE HADOOP
Real Time Processing / Analytics
Hadoop is really good for big data ingestion/storage. But the caveat is that Hadoop works on batch processing, hence response time is high. Therefore, Hadoop alone is note suitable for real-time processing/analytics, but you can always mount an spark over it and get the job done:
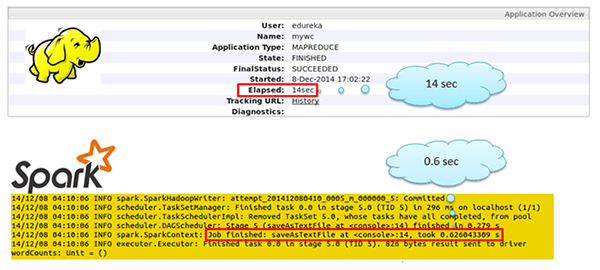
For the record, Spark is said to be 100 times faster than Hadoop. Oh yes, I said 100 times faster it is not a typo. The diagram below shows the comparison between MapReduce processing and processing using Spark
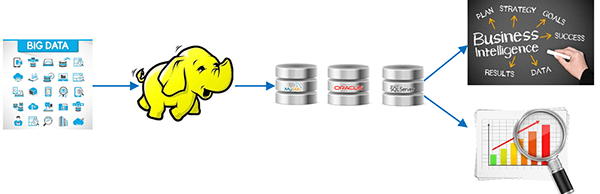
Not a Replacement for Existing Infrastructure
All the historical big data can be stored in Hadoop HDFS and it can be processed and transformed into a structured manageable data. After processing the data in Hadoop you need to send the output to relational database technologies for BI, decision support, reporting etc.
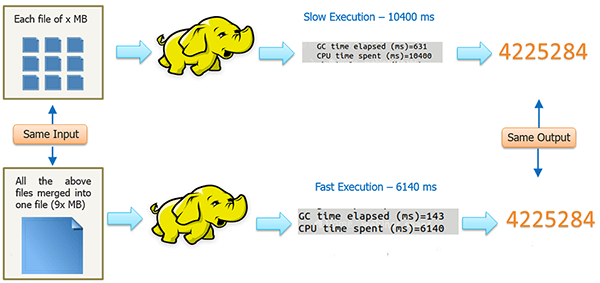
Multiple Smaller Datasets
Hadoop framework is not recommended for small-structured datasets.
In this case, since all the small files (for example, Server daily logs ) is of the same format, structure and the processing to be done on them is same, we can merge all the small files into one big file and then finally run our MapReduce program on it.
Where Security is the primary Concern
There are multiple ways to ensure that your sensitive data is secure with the elephant (Hadoop).
- Encrypt your data while moving to Hadoop. You can easily write a MapReduce program using any encryption Algorithm which encrypts the data and stores it in HDFS.
https://www.edureka.co/blog/5-reasons-when-to-use-and-not-to-use-hadoop/
https://hadoopecosystemtable.github.io/
https://braindump.jethro.dev/posts/hadoop/
https://elephantscale.com/wp-content/uploads/2020/05/hadoop-illuminated.pdf