MapReduce Architecture in Big Data explained with Example
The whole process goes through four phases of execution namely, splitting, mapping, shuffling, and reducing.
Input Splits:
An input to a MapReduce in Big Data job is divided into fixed-size pieces called **input splits **Input split is a chunk of the input that is consumed by a single map
Mapping
This is the very first phase in the execution of map-reduce program. In this phase data in each split is passed to a mapping function to produce output values. In our example, a job of mapping phase is to count a number of occurrences of each word from input splits (more details about input-split is given below) and prepare a list in the form of <word, frequency>
Shuffling
This phase consumes the output of Mapping phase. Its task is to consolidate the relevant records from Mapping phase output. In our example, the same words are clubed together along with their respective frequency.
Reducing
In this phase, output values from the Shuffling phase are aggregated. This phase combines values from Shuffling phase and returns a single output value. In short, this phase summarizes the complete dataset.
Consider you have following input data for your MapReduce in Big data Program:
Welcome to Hadoop Class
Hadoop is good
Hadoop is bad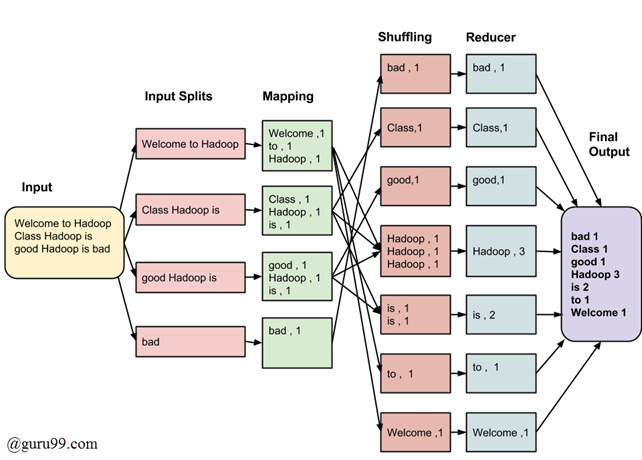
The final output of the MapReduce task is:
| bad | 1 |
|---|---|
| Class | 1 |
| good | 1 |
| Hadoop | 3 |
| is | 2 |
| to | 1 |
| Welcome | 1 |
https://www.guru99.com/introduction-to-mapreduce.html