There are two basic techniques that can be applied to a data set:
- It can be split over multiple nodes (partitioning) to allow for more parallel processing.
- It can be copied or cached on different nodes to reduce the distance between the client and the server and for greater fault tolerance (replication).
Divide and conquer - I mean, partition and replicate.
The picture below illustrates the difference between these two: partitioned data (A and B below) is divided into independent sets, while replicated data (C below) is copied to multiple locations.
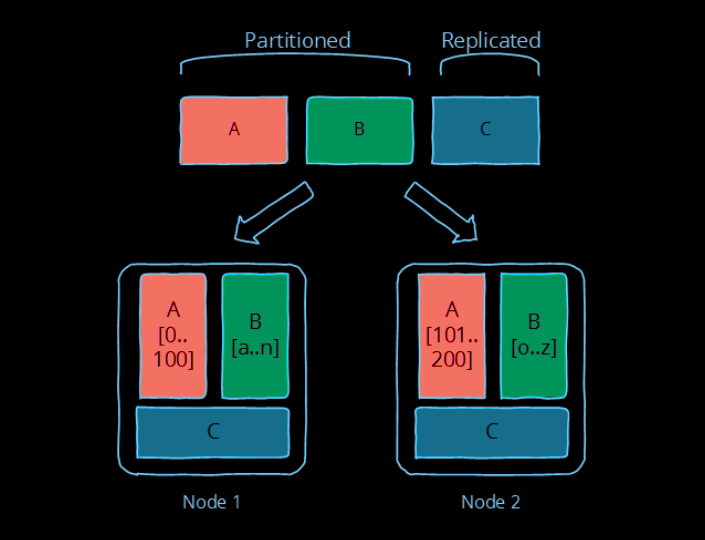
Of course, the trick is in picking the right technique for your concrete implementation.
PARTITIONING
Partitioning is dividing the dataset into smaller distinct independent sets;
- this is used to reduce the impact of dataset growth since each partition is a subset of the data.
- Partitioning improves performance by limiting the amount of data to be examined and by locating related data in the same partition
- Partitioning improves availability by allowing partitions to fail independently, increasing the number of nodes that need to fail before availability is sacrificed
Partitioning is mostly about defining your partitions based on what you think the primary access pattern will be, and dealing with the limitations that come from having independent partitions (e.g. inefficient access across partitions, different rate of growth etc.).
REPLICATION
Replication is making copies of the same data on multiple machines; this allows more servers to take part in the computation.
Replication - copying or reproducing something - is the primary way in which we can fight latency.
- Replication improves performance by making additional computing power and bandwidth applicable to a new copy of the data
- Replication improves availability by creating additional copies of the data, increasing the number of nodes that need to fail before availability is sacrificed
Replication is about providing extra bandwidth, and caching where it counts. It is also about maintaining consistency in some way according to some consistency model.
Replication allows us to achieve scalability, performance and fault tolerance. Afraid of loss of availability or reduced performance? Replicate the data to avoid a bottleneck or single point of failure. Slow computation? Replicate the computation on multiple systems. Slow I/O? Replicate the data to a local cache to reduce latency or onto multiple machines to increase throughput.
Replication is also the source of many of the problems, since there are now independent copies of the data that has to be kept in sync on multiple machines - this means ensuring that the replication follows a consistency model.
The choice of a consistency model is crucial