(NEW) Real-time multi-core virtual machine scheduling in xen
https://github.com/PandaMengXu/RT-Xen
https://github.com/xisisu/RT-Xen
https://sites.google.com/site/realtimexen/publications
https://dl.acm.org/doi/10.1145/2038642.2038651
The VMM must ensure that every running guest OS receives an appropriate amount of CPU time. The main scheduling abstraction in Xen is the virtual CPU (VCPU), which appears as a normal CPU to each guest OS. To take ad- vantage of symmetric multiprocessing, each domain can be configured with one or more VCPUs, up to the number of underlying physical cores. A VCPU in Xen is analogous to a process in a traditional operating system. Just as the scheduler in a traditional operating system switches among processes as they become ready or blocked, the scheduler in Xen switches among VCPUs.
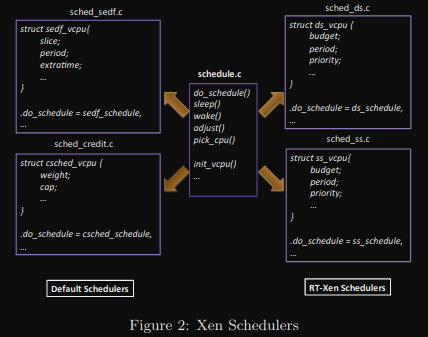
A common schedule.c file defines the framework for the Xen scheduler, which contains several functions including do schedule, sleep, wake, etc. To implement a specific scheduling algorithm, a developer needs to implement a subscheduler file(for example, sched credit.c) which defines all these functions, and then hook them up to the Xen scheduling framework.
A developer can also design specific VCPU data structures in the subscheduler file. Among these functions, the most important ones for real-time performance are:
*do_schedule*- This function decides which VCPU should be running next, and returns its identity along with the amount of time for which to run it.
*wake*- When a domain receives a task to run, the wake function is called; usually it will insert the VCPU into the CPU’s RunQ (a queue containing all the runnable VCPUs), and if it has higher priority than the cur- rently running one, an interrupt is raised to trigger the do schedule function to perform the context switch.
*pick_cpu*- According to the domain’s VCPU settings, this function chooses on which physical core the VCPU should be running; if it is different from the current one, a VCPU migration is triggered.
*sleep*- This function is called when any guest OS is paused, and removes the VCPU from the RunQ
Xen currently ships with two schedulers: the Credit scheduler and the Simple EDF (SEDF) scheduler. The Credit scheduler is used by default from Xen 3.0 onward, and provides a form of proportional share scheduling. In the Credit scheduler, every physical core has one Run Queue (RunQ), which holds all the runnable VCPUs (VCPU with a task to run). An IDLE VCPU for each physical core is also created at boot time. It is always runnable and is always put at the end of the RunQ. When the IDLE VCPU is scheduled, the physical core becomes IDLE. Each domain con- tains two parameters: weight and cap, as shown in Figure 2. Weight defines its proportional share, and cap defines the upper limit of its execution time. At the beginning of an ac- counting period, each domain is given credit according to its weight, and the domain distributes the credit to its VCPUs. VCPUs consume credit as they run, and are divided into three categories when on the RunQ: BOOST, UNDER, and OVER. A VCPU is put into the BOOST category when it performs I/O, UNDER if it has remaining credit, and OVER if runs out of credit. The scheduler picks VCPUs in the order of BOOST, UNDER, and OVER. Within each category, it is important to note that VCPUs are scheduled in a round robin fashion. By default, when picking a VCPU, the scheduler allows it to run for 30 ms, and then triggers the do scheduler function again to pick the next one. This quantum involves tradeoffs between real-time performance and throughput.
Each guest OS is responsible for scheduling its tasks. The current implementation of RT-Xen supports Linux. To be consistent with existing hierarchical scheduling analysis [15], we used the preemptive fixed-priority scheduling class in Linux to schedule the tasks in the experiments described in Section 5. Each guest OS is allocated one VCPU. As [10] shows, using a dedicated core to deal with interrupts can greatly improve system performance, so we bind domain 0 to a dedicated core, and bind all other guest operating systems to another core to minimize interference, as we discuss in more detail in Section 4.2.
We now describe how the four RT-Xen schedulers (Deferrable Server, Periodic Server, Polling Server and Sporadic Server) are implemented. We assume that every guest OS is equipped with one VCPU, and all the guest OSes are pinned on one specific physical core. In all four schedulers, each VCPU has three parameters: budget, period, and priority. Since the Deferrable, Periodic, and Polling Servers all share the same replenishment rules, we can implement them as one sub- scheduler, and have developed a tool to switch between them on the fly.
## IMPLEMENTATION OVERVIEW
Let’s see how this bad boy do it’s magic:
First, the new scheduler functions are defined at xen/common/sched_rt.c
The most important structure here is the sched_rtds_def struct, where all the functions used by the XEN scheduler framework are defined
(this is how the C implements the concept of interface like GO or JAVA brrrrr)
const struct scheduler sched_rtds_def = {
.name = "SMP RTDS Scheduler",
.opt_name = "rtds",
.sched_id = XEN_SCHEDULER_RTDS,
.sched_data = &_rt_priv,
.dump_cpu_state = rt_dump_pcpu,
.dump_settings = rt_dump,
.init = rt_init,
.deinit = rt_deinit,
.alloc_pdata = rt_alloc_pdata,
.free_pdata = rt_free_pdata,
.alloc_domdata = rt_alloc_domdata,
.free_domdata = rt_free_domdata,
.init_domain = rt_dom_init,
.destroy_domain = rt_dom_destroy,
.alloc_vdata = rt_alloc_vdata,
.free_vdata = rt_free_vdata,
.insert_vcpu = rt_vcpu_insert,
.remove_vcpu = rt_vcpu_remove,
.adjust = rt_dom_cntl,
.adjust_global = rt_sys_cntl,
.pick_cpu = rt_cpu_pick,
.do_schedule = rt_schedule,
.sleep = rt_vcpu_sleep,
.wake = rt_vcpu_wake,
.context_saved = rt_context_saved,
};So, if you check the scheduler array (used to hold all schedulers definitions) defined at xen/common/schedule.c, you can see our bad boy included:
static const struct scheduler *schedulers[] = {
&sched_credit_def,
&sched_credit2_def,
&sched_arinc653_def,
&sched_rtds_def,
};