A technical report on convolution arithmetic in the context of deep learning:
https://github.com/vdumoulin/conv_arithmetic
ARCHITECTURE:
Existing between the convolution and the pooling layer is an activation function such as the ReLu layer; a non-saturating activation is applied element-wise, thresholding at zero. After several convolutional and pooling layers, the image size (feature map size) is reduced and more complex features are extracted.
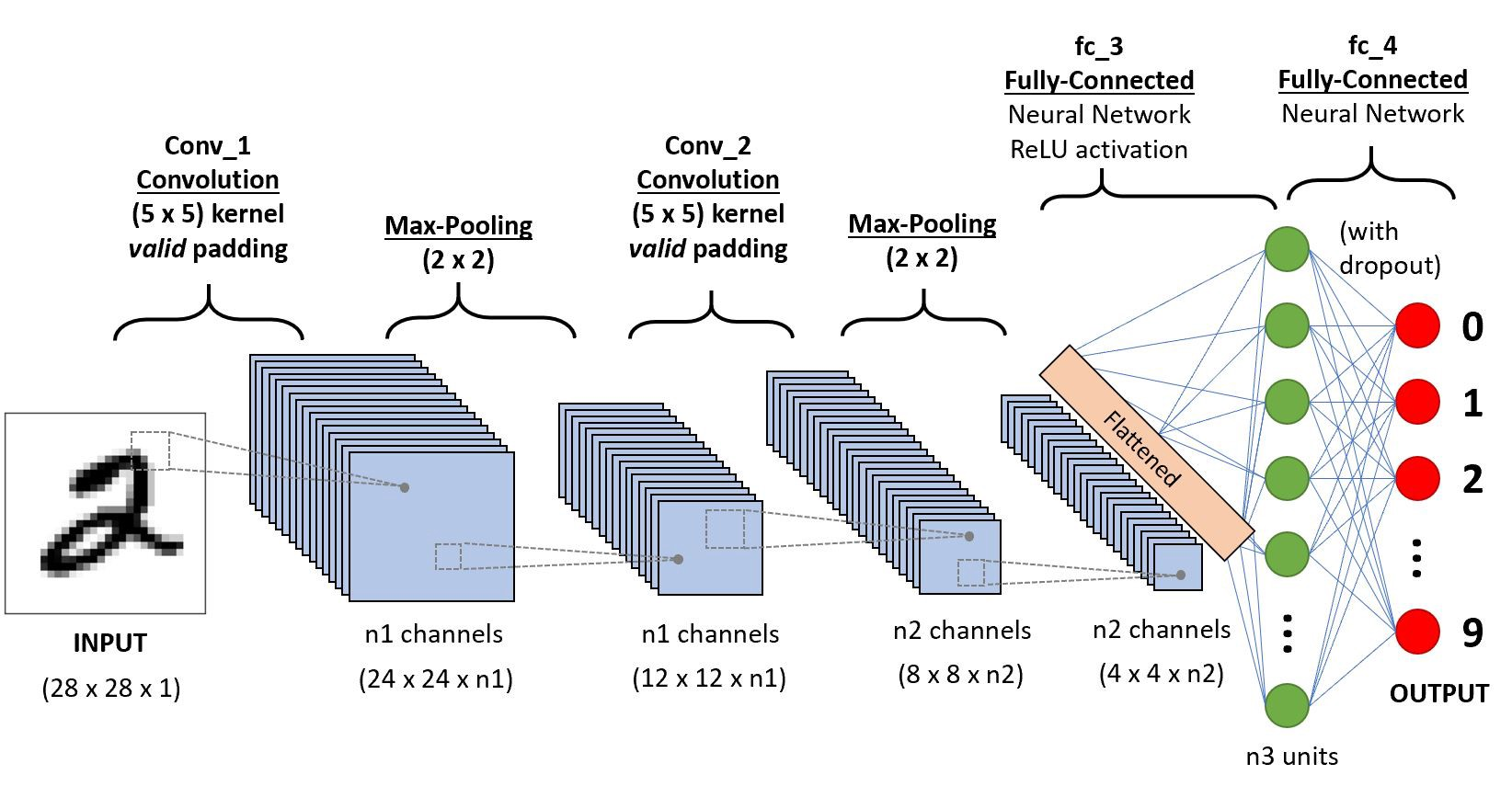
Eventually with a small enough feature map, the contents are squashed into a one dimension vector and fed into a fully-connected MLP for processing. The last layer of this fully-connected MLP seen as the output, is a loss layer which is used to specify how the network training penalizes the deviation between the predicted and true labels.

Convolutional neural networks employ a weight sharing strategy that leads to a significant reduction in the number of parameters that have to be learned. The presence of larger receptive field sizes of neurons in successive convolutional layers coupled with the presence of pooling layers also lead to translation invariance.
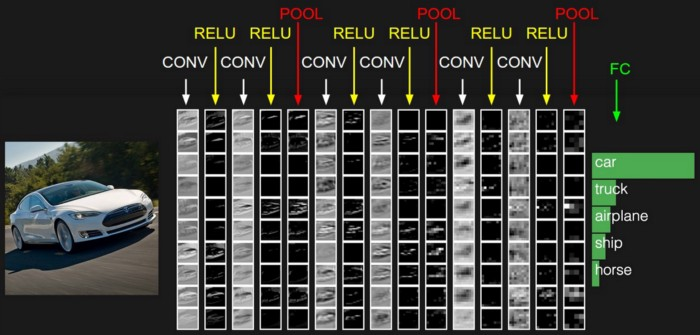
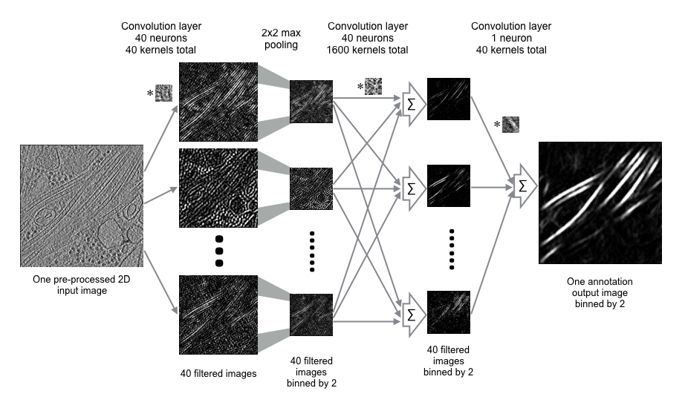
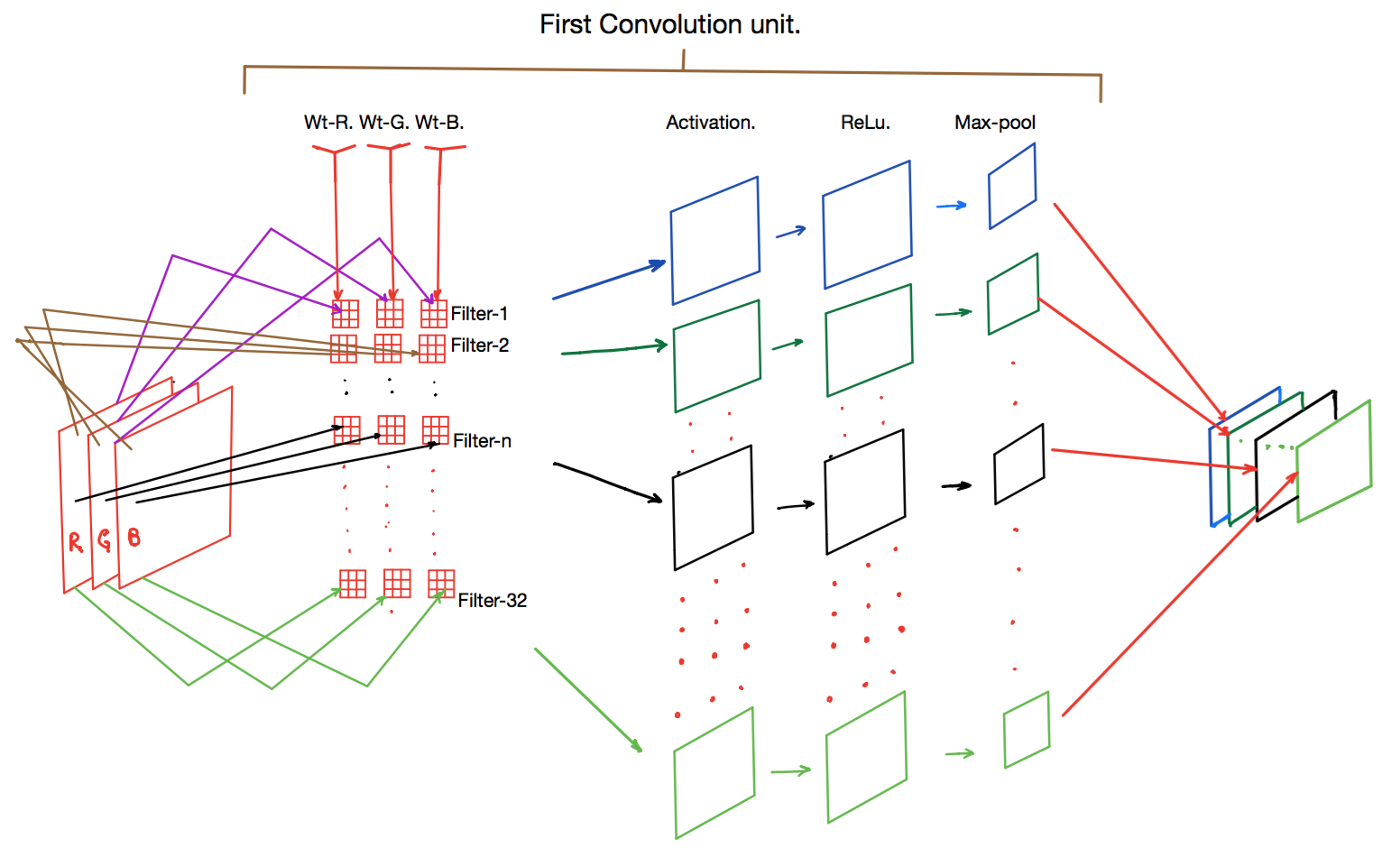
Convolutional networks are built from several types of layers:
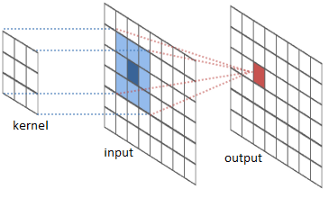
- Conv2D - performs convolution:
- The convolutional layer serves to detect (multiple) patterns in multipe sub-regions in the input field using receptive fields.
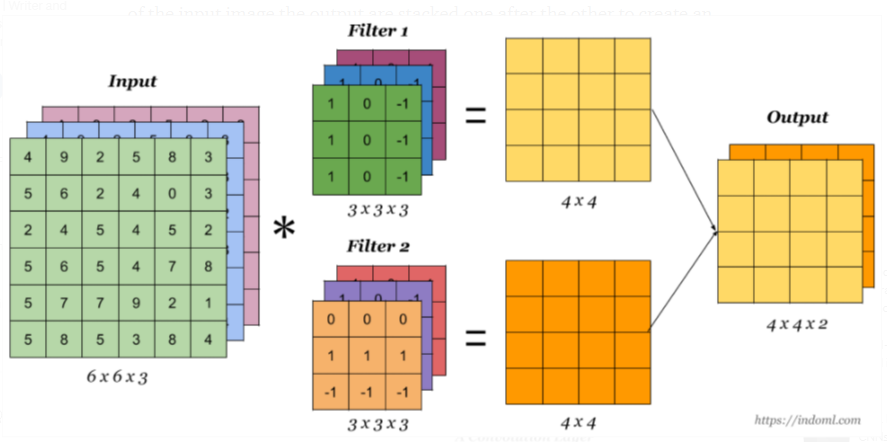
- **filters**: number of output channels;
- **kernel_size**: an integer or tuple/list of 2 integers, specifying the width and height of the 2D convolution window;
- **padding**: padding=“same” adds zero padding to the input, so that the output has the same width and height, padding=‘valid’ performs convolution only in locations where kernel and the input fully overlap;
- **activation**: “relu”, “tanh”, etc.
- **input_shape**: shape of input.
- MaxPooling2D - performs 2D max pooling.
- The pooling layer serves to progressively reduce the spatial size of the representation, to reduce the number of parameters and amount of computation in the network, and hence to also control overfitting.
- The intuition is that the exact location of a feature is less important than its rough location relative to other features.

Just to be clear, conv layers and pooling layers might seem to do the same shit, but the point is that conv-layer has parameters to learn (that is your weights which you update each step), whereas the pooling layer does not - it is just applying some given function e.g max-function.
-
Flatten - flattens the input, does not affect the batch size.
- A Flatten layer reshapes the tensor to have a shape that is equal to the number of elements contained in the tensor.
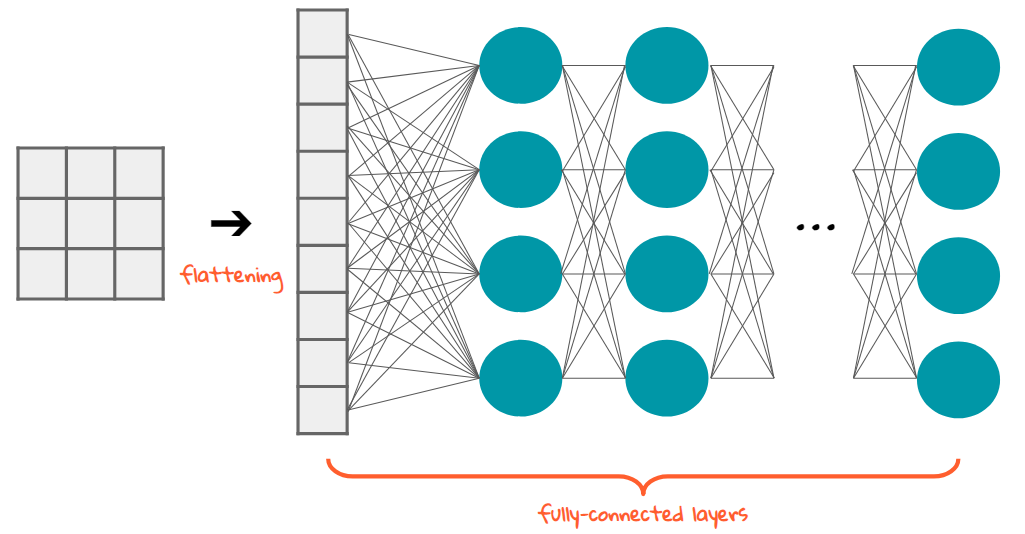
- A Flatten layer reshapes the tensor to have a shape that is equal to the number of elements contained in the tensor.
-
Dense - fully-connected layer.
- A “dense layer” is a layer that is deeply connected with its preceding layer which means the neurons of the layer are connected to every neuron of its preceding layer
- Dense Layer is used to classify image based on output from convolutional layers.
-
Activation - applies an activation function.
- Activation layers are not technically “layers” (due to the fact that no parameters/weights are learned inside an activation layer) and are sometimes omitted from network architecture diagrams as it’s *assumed *that an activation *immediately follows *a convolution.
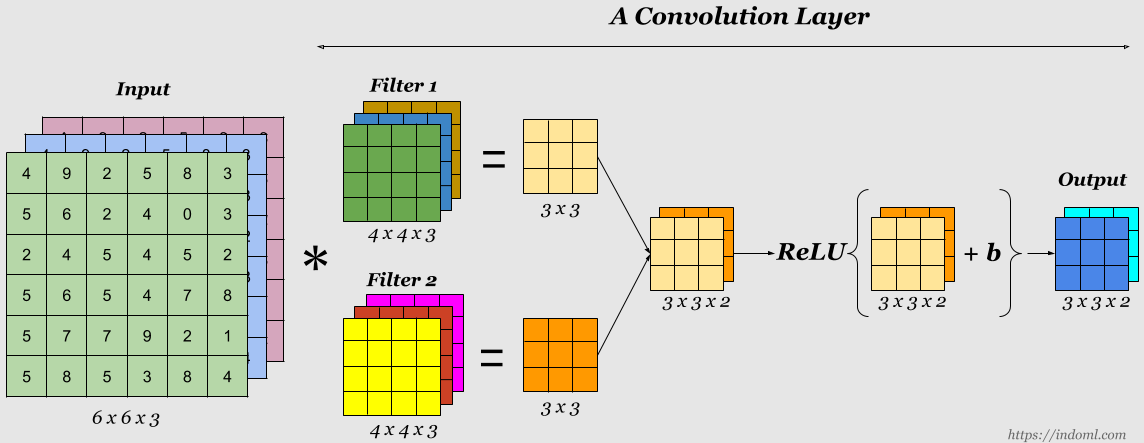
- For every neural network we have to apply activation function to find out which node should be fired.
- LeakyReLU - applies leaky relu activation.
- Activation layers are not technically “layers” (due to the fact that no parameters/weights are learned inside an activation layer) and are sometimes omitted from network architecture diagrams as it’s *assumed *that an activation *immediately follows *a convolution.
-
Dropout - applies dropout.
- Dropout is actually a form of *regularization *that aims to help prevent overfitting by increasing testing accuracy, perhaps at the expense of training accuracy.
- The Dropout layer is a mask that nullifies the contribution of some neurons towards the next layer and leaves unmodified all others.
- Dropout layers are important in training CNNs because they prevent overfitting on the training data. If they aren’t present, the first batch of training samples influences the learning in a disproportionately high manner. This, in turn, would prevent the learning of features that appear only in later samples or batches:
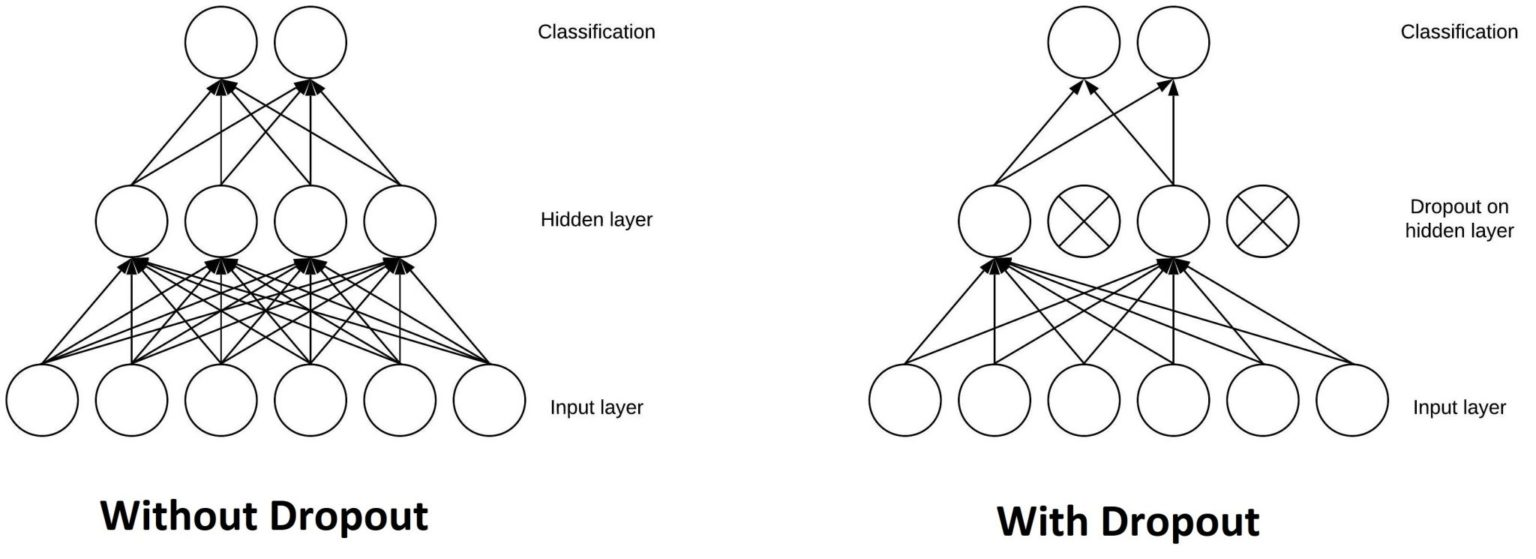
- The reason we apply dropout is to reduce overfitting by *explicitly *altering the network architecture at training time. Randomly dropping connections ensures that no single node in the network is responsible for “activating” when presented with a given pattern. Instead, dropout ensures there are *multiple, redundant nodes *that will activate when presented with similar inputs — this, in turn, helps our model to *generalize*.
week3_task1_first_cnn_cifar10_clean.ipynb